پیاده سازی نگاشت کاهش (MapReduce) در پایتون — به زبان ساده
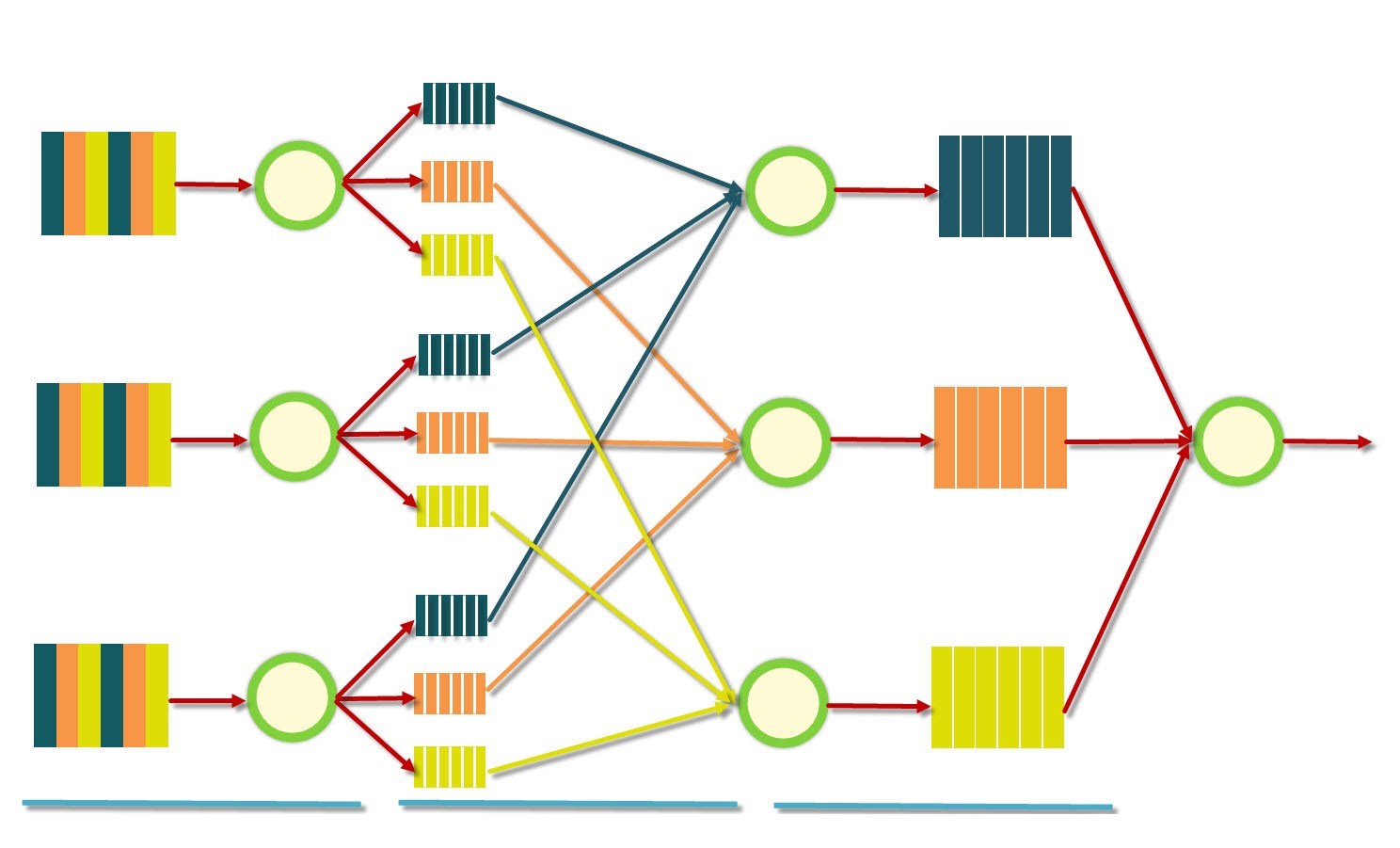
«نگاشت کاهش» (MapReduce)، یک مدل بینظیر است که پردازش مجموعه دادههای دارای نمونههای زیاد (مجموعه دادههای بزرگ) را آسانتر کرده است. این مدل، کاربردهای متعددی در مسائل تحلیل داده دارد و در مسائل جهان واقعی متعددی مورد استفاده قرار میگیرد. از این رو، در این مطلب روش پیاده سازی نگاشت کاهش در زبان برنامهنویسی پایتون شرح داده شده است. همچنین، مدل در یک پروژه عملی مورد بررسی قرار گرفته است. در این پروژه، تعداد کلمات کتاب رمان «Unveiling a Parallel» شمارش خواهد شد. در ادامه، برخی از پیشنیازهای لازم و موجود برای پیادهسازی این کد بیان شده است.
- ماژول «چندپردازشی» (multiprocessing) برای پخش کردن پردازشها، که با فراخوانی متد ()start روی شی Process ساخته شده مورد استفاده قرار میگیرد.
- یک فایل خروجی متناظر با هر «رشته اجرایی» (thread) «کاهش» (Reduce) وجود دارد.
- خروجیها را میتوان در پایان در یک فایل یکتا ادغام کرد.
- نتایج گام نگاشت (map)، با استفاده از «نشانهگذاری شی جاوا اسکریپت» (نشانهگذاری شی جاوا اسکریپت | JSON) ذخیره میشوند (مانند فایلهای خروجی برای هر رشته اجرایی خروجی).
کاربر در پایان ممکن است تصمیم بگیرد که این فایلها را حذف و یا رها کند.
پیاده سازی نگاشت کاهش (MapReduce)
ابتدا، اولین کاری که باید انجام شود نوشتن کلاس MapReduce است که نقش رابط را برای پیادهسازی شدن توسط کاربر، دارد. این کلاس دارای دو متد است: mapper و reducer که بعدا پیادهسازی خواهند شد (مثالی از پیادهسازی یک شمارنده لغات با استفاده از MapReduce در ادامه و در بخش مثال شمارنده کلمات، ارائه شده است).

بنابراین، کار نوشتن الگوریتم، با نوشتن کد زیر آغاز میشود:
1import settings
2class MapReduce(object):
3 """MapReduce class representing the mapreduce model
4 note: the 'mapper' and 'reducer' methods must be
5 implemented to use the mapreduce model.
6 """
7 def __init__(self, input_dir = settings.default_input_dir, output_dir = settings.default_output_dir,
8 n_mappers = settings.default_n_mappers, n_reducers = settings.default_n_reducers,
9 clean = True):
10 """
11 :param input_dir: directory of the input files,
12 taken from the default settings if not provided
13 :param output_dir: directory of the output files,
14 taken from the default settings if not provided
15 :param n_mappers: number of mapper threads to use,
16 taken from the default settings if not provided
17 :param n_reducers: number of reducer threads to use,
18 taken from the default settings if not provided
19 :param clean: optional, if True temporary files are
20 deleted, True by default.
21 """
22 self.input_dir = input_dir
23 self.output_dir = output_dir
24 self.n_mappers = n_mappers
25 self.n_reducers = n_reducers
26 self.clean = clean
27 def mapper(self, key, value):
28 """outputs a list of key-value pairs, where the key is
29 potentially new and the values are of a potentially different type.
30 Note: this function is to be implemented.
31 :param key:
32 :param value:
33 """
34 pass
35 def reducer(self, key, values_list):
36 """Outputs a single value together with the provided key.
37 Note: this function is to be implemented.
38 :param key:
39 :param value_list:
40 """
41 passبرای بررسی تنظیمات گوناگون، باید ماژول «تنظیمات» (settings) را بررسی کرد. سپس، نیاز به افزودن متد ()run برای کلاس MapReduce است که عملیات map و reduce را اجرا میکند. بدین منظور، نیاز به تعریف یک متد (run_mapper(index است (که در آن، index به رشته اجرایی کنونی ارجاع دارد) که از mapper استفاده میکند و نتایج را روی دیسک ذخیره میکند و (run_reducer(index که reducer را روی نتایج map اعمال و نتایج رار وی دیسک ذخیره میکند.

متد ()run تعداد دلخواهی از نگاشتکنندهها (mappers) و سپس، تعداد لازم از کاهشدهندهها (reducers) را پخش میکند. شی Process از ماژول multiprocessing به صورت زیر مورد استفاده قرار میگیرد.
1def run_mapper(self, index):
2 """Runs the implemented mapper
3 :param index: the index of the thread to run on
4 """
5 # read a key
6 # read a value
7 # get the result of the mapper
8 # store the result to be used by the reducer
9 pass
10def run_reducer(self, index):
11 """Runs the implemented reducer
12 :param index: the index of the thread to run on
13 """
14 # load the results of the map
15 # for each key reduce the values
16 # store the results for this reducer
17 pass
18def run(self):
19 """Executes the map and reduce operations
20 """
21 # initialize mappers list
22 map_workers = []
23 # initialize reducers list
24 rdc_workers = []
25 # run the map step
26 for thread_id in range(self.n_mappers):
27 p = Process(target=self.run_mapper, args=(thread_id,))
28 p.start()
29 map_workers.append(p)
30 [t.join() for t in map_workers]
31 # run the reduce step
32 for thread_id in range(self.n_reducers):
33 p = Process(target=self.run_reducer, args=(thread_id,))
34 p.start()
35 map_workers.append(p)
36 [t.join() for t in rdc_workers]اکنون، باید متدهای run_mapper و run_reducer را تکمیل کرد. اما، از آنجا که این متدها نیازمند خواندن و ذخیره دادهها از یک فایل ورودی هستند، ابتدا باید یک کلاس FileHandler ساخت. این کلاس، فایل ورودی را با استفاده از متد split_file (همان number_of_splits) (که در آن تعداد تقسیمات یا همان number of splits، تعداد کل بخشهایی است که به عنوان نتیجه تقسیمبندی مورد نیاز هستند) تقسیمبندی میکند. کلاس FileHandler نیز با استفاده از متد join_files (داریم number_of_files ,clean ,sort ,decreasing) به خروجیها میپیوندد (که در آن number_of_files تعداد کل فایلها برای join است.
clean ،sort و decreasing مجموعه همه آرگومانهای بولی دلخواه هستند که در این مثال، همه به طور پیشفرض در حالت True قرار دارند). clean بیان میکند که کاربر کجا میخواهد فایلهای موقتی را بعد از join حذف کند، sort نشان میدهد که آیا نتایج مرتب شده یا نه و decreasing نشان میدهد که کاربر میخواهد مرتبسازی را به ترتیب معکوس انجام دهد یا خیر. باید این موضوع را به خاطر داشت که کار با نوشتن شی FileHandler به صورت زیر، آغاز شده است:
1class FileHandler(object):
2 """FileHandler class
3 Manages splitting input files and joining outputs together.
4 """
5 def __init__(self, input_file_path, output_dir):
6 """
7 Note: the input file path should be given for splitting.
8 The output directory is needed for joining the outputs.
9 :param input_file_path: input file path
10 :param output_dir: output directory path
11 """
12 self.input_file_path = input_file_path
13 self.output_dir = output_dir
14 def split_file(self, number_of_splits):
15 """split a file into multiple files.
16 :param number_of_splits: the number of splits.
17 """
18 pass
19 def join_files(self, number_of_files, clean = None, sort = True, decreasing = True):
20 """join all the files in the output directory into a
21 single output file.
22 :param number_of_files: total number of files.
23 :param clean: if True the reduce outputs will be deleted,
24 by default takes the value of self.clean.
25 :param sort: sort the outputs.
26 :param decreasing: sort by decreasing order, high value
27 to low value.
28 :return output_join_list: a list of the outputs
29 """
30 passسپس، نوشتن متدهای split و join کامل میشود.
1import os
2import json
3
4class FileHandler(object):
5 """FileHandler class
6 Manages splitting input files and joining outputs together.
7 """
8 def __init__(self, input_file_path, output_dir):
9 """
10 Note: the input file path should be given for splitting.
11 The output directory is needed for joining the outputs.
12 :param input_file_path: input file path
13 :param output_dir: output directory path
14 """
15 self.input_file_path = input_file_path
16 self.output_dir = output_dir
17 def begin_file_split(self, split_index, index):
18 """initialize a split file by opening and adding an index.
19 :param split_index: the split index we are currently on, to be used for naming the file.
20 :param index: the index given to the file.
21 """
22 file_split = open(settings.get_input_split_file(split_index-1), "w+")
23 file_split.write(str(index) + "\n")
24 return file_split
25 def is_on_split_position(self, character, index, split_size, current_split):
26 """Check if it is the right time to split.
27 i.e: character is a space and the limit has been reached.
28 :param character: the character we are currently on.
29 :param index: the index we are currently on.
30 :param split_size: the size of each single split.
31 :param current_split: the split we are currently on.
32 """
33 return index>split_size*current_split+1 and character.isspace()
34 def split_file(self, number_of_splits):
35 """split a file into multiple files.
36 note: this has not been optimized to avoid overhead.
37 :param number_of_splits: the number of chunks to
38 split the file into.
39 """
40 file_size = os.path.getsize(self.input_file_path)
41 unit_size = file_size / number_of_splits + 1
42 original_file = open(self.input_file_path, "r")
43 file_content = original_file.read()
44 original_file.close()
45 (index, current_split_index) = (1, 1)
46 current_split_unit = self.begin_file_split(current_split_index, index)
47 for character in file_content:
48 current_split_unit.write(character)
49 if self.is_on_split_position(character, index, unit_size, current_split_index):
50 current_split_unit.close()
51 current_split_index += 1
52 current_split_unit = self.begin_file_split(current_split_index,index)
53 index += 1
54 current_split_unit.close()اکنون، میتوان متدهای run_mapper و run_reducer را مانند زیر کامل کرد:
1def run_mapper(self, index):
2 """Runs the implemented mapper
3 :param index: the index of the thread to run on
4 """
5 input_split_file = open(settings.get_input_split_file(index), "r")
6 key = input_split_file.readline()
7 value = input_split_file.read()
8 input_split_file.close()
9 if(self.clean):
10 os.unlink(settings.get_input_split_file(index))
11 mapper_result = self.mapper(key, value)
12 for reducer_index in range(self.n_reducers):
13 temp_map_file = open(settings.get_temp_map_file(index, reducer_index), "w+")
14 json.dump([(key, value) for (key, value) in mapper_result
15 if self.check_position(key, reducer_index)]
16 , temp_map_file)
17 temp_map_file.close()
18
19def run_reducer(self, index):
20 """Runs the implemented reducer
21 :param index: the index of the thread to run on
22 """
23 key_values_map = {}
24 for mapper_index in range(self.n_mappers):
25 temp_map_file = open(settings.get_temp_map_file(mapper_index, index), "r")
26 mapper_results = json.load(temp_map_file)
27 for (key, value) in mapper_results:
28 if not(key in key_values_map):
29 key_values_map[key] = []
30 try:
31 key_values_map[key].append(value)
32 except Exception, e:
33 print "Exception while inserting key: "+str(e)
34 temp_map_file.close()
35 if self.clean:
36 os.unlink(settings.get_temp_map_file(mapper_index, index))
37 key_value_list = []
38 for key in key_values_map:
39 key_value_list.append(self.reducer(key, key_values_map[key]))
40 output_file = open(settings.get_output_file(index), "w+")
41 json.dump(key_value_list, output_file)
42 output_file.close()در نهایت، متد run اندکی ویرایش میشود تا کاربر قادر به تعیین این باشد که خروجیها متصل شوند یا خیر. متد run به صورت زیر میشود:
1def run(self, join=False):
2 """Executes the map and reduce operations
3 :param join: True if we need to join the outputs, False by default.
4 """
5 # initialize mappers list
6 map_workers = []
7 # initialize reducers list
8 rdc_workers = []
9 # run the map step
10 for thread_id in range(self.n_mappers):
11 p = Process(target=self.run_mapper, args=(thread_id,))
12 p.start()
13 map_workers.append(p)
14 [t.join() for t in map_workers]
15 # run the reduce step
16 for thread_id in range(self.n_reducers):
17 p = Process(target=self.run_reducer, args=(thread_id,))
18 p.start()
19 map_workers.append(p)
20 [t.join() for t in rdc_workers]
21 if join:
22 self.join_outputs()کد نهایی الگوریتم نگاشت کاهش (Map Reduce)، در زبان برنامهنویسی پایتون، به صورت زیر خواهد بود:
1import os
2import json
3import settings
4from multiprocessing import Process
5
6
7class FileHandler(object):
8 """FileHandler class
9 Manages splitting input files and joining outputs together.
10
11 """
12 def __init__(self, input_file_path, output_dir):
13 """
14 Note: the input file path should be given for splitting.
15 The output directory is needed for joining the outputs.
16 :param input_file_path: input file path
17 :param output_dir: output directory path
18 """
19 self.input_file_path = input_file_path
20 self.output_dir = output_dir
21
22 def initiate_file_split(self, split_index, index):
23 """initialize a split file by opening and adding an index.
24 :param split_index: the split index we are currently on, to be used for naming the file.
25 :param index: the index given to the file.
26 """
27 file_split = open(settings.get_input_split_file(split_index-1), "w+")
28 file_split.write(str(index) + "\n")
29 return file_split
30
31 def is_on_split_position(self, character, index, split_size, current_split):
32 """Check if it is the right time to split.
33 i.e: character is a space and the limit has been reached.
34 :param character: the character we are currently on.
35 :param index: the index we are currently on.
36 :param split_size: the size of each single split.
37 :param current_split: the split we are currently on.
38 """
39 return index>split_size*current_split+1 and character.isspace()
40
41 def split_file(self, number_of_splits):
42 """split a file into multiple files.
43 note: this has not been optimized to avoid overhead.
44 :param number_of_splits: the number of chunks to
45 split the file into.
46 """
47 file_size = os.path.getsize(self.input_file_path)
48 unit_size = file_size / number_of_splits + 1
49 original_file = open(self.input_file_path, "r")
50 file_content = original_file.read()
51 original_file.close()
52 (index, current_split_index) = (1, 1)
53 current_split_unit = self.initiate_file_split(current_split_index, index)
54 for character in file_content:
55 current_split_unit.write(character)
56 if self.is_on_split_position(character, index, unit_size, current_split_index):
57 current_split_unit.close()
58 current_split_index += 1
59 current_split_unit = self.initiate_file_split(current_split_index, index)
60 index += 1
61 current_split_unit.close()
62
63 def join_files(self, number_of_files, clean = False, sort = True, decreasing = True):
64 """join all the files in the output directory into a
65 single output file.
66 :param number_of_files: total number of files.
67 :param clean: if True the reduce outputs will be deleted,
68 by default takes the value of self.clean.
69 :param sort: sort the outputs.
70 :param decreasing: sort by decreasing order, high value
71 to low value.
72 :return output_join_list: a list of the outputs
73 """
74 output_join_list = []
75 for reducer_index in xrange(0, number_of_files):
76 f = open(settings.get_output_file(reducer_index), "r")
77 output_join_list += json.load(f)
78 f.close()
79 if clean:
80 os.unlink(settings.get_output_file(reducer_index))
81 if sort:
82 from operator import itemgetter as operator_ig
83 # sort using the key
84 output_join_list.sort(key=operator_ig(1), reverse=decreasing)
85 output_join_file = open(settings.get_output_join_file(self.output_dir), "w+")
86 json.dump(output_join_list, output_join_file)
87 output_join_file.close()
88 return output_join_list
89
90class MapReduce(object):
91 """MapReduce class
92 Note: mapper and reducer functions need to be implemented.
93
94 """
95
96 def __init__(self, input_dir = settings.default_input_dir, output_dir = settings.default_output_dir,
97 n_mappers = settings.default_n_mappers, n_reducers = settings.default_n_reducers,
98 clean = True):
99 """
100 :param input_dir: directory of the input files,
101 taken from the default settings if not provided
102 :param output_dir: directory of the output files,
103 taken from the default settings if not provided
104 :param n_mappers: number of mapper threads to use,
105 taken from the default settings if not provided
106 :param n_reducers: number of reducer threads to use,
107 taken from the default settings if not provided
108 :param clean: optional, if True temporary files are
109 deleted, True by default.
110 """
111 self.input_dir = input_dir
112 self.output_dir = output_dir
113 self.n_mappers = n_mappers
114 self.n_reducers = n_reducers
115 self.clean = clean
116 self.file_handler = FileHandler(settings.get_input_file(self.input_dir), self.output_dir)
117 self.file_handler.split_file(self.n_mappers)
118
119 def mapper(self, key, value):
120 """outputs a list of key-value pairs, where the key is
121 potentially new and the values are of a potentially different type.
122 Note: this function is to be implemented.
123 :param key: key of the current mapper
124 :param value: value for the corresponding key
125 note: this method should be implemented
126 """
127 pass
128
129 def reducer(self, key, values_list):
130 """Outputs a single value together with the provided key.
131 Note: this function is to be implemented.
132 :param key: key of the reducer
133 :param value_list: list of values for the key
134 note: this method should be implemented
135 """
136 pass
137
138 def check_position(self, key, position):
139 """Checks if we are on the right position
140 """
141 return position == (hash(key) % self.n_reducers)
142
143 def run_mapper(self, index):
144 """Runs the implemented mapper
145 :param index: the index of the thread to run on
146 """
147 input_split_file = open(settings.get_input_split_file(index), "r")
148 key = input_split_file.readline()
149 value = input_split_file.read()
150 input_split_file.close()
151 if(self.clean):
152 os.unlink(settings.get_input_split_file(index))
153 mapper_result = self.mapper(key, value)
154 for reducer_index in range(self.n_reducers):
155 temp_map_file = open(settings.get_temp_map_file(index, reducer_index), "w+")
156 json.dump([(key, value) for (key, value) in mapper_result
157 if self.check_position(key, reducer_index)]
158 , temp_map_file)
159 temp_map_file.close()
160
161 def run_reducer(self, index):
162 """Runs the implemented reducer
163 :param index: the index of the thread to run on
164 """
165 key_values_map = {}
166 for mapper_index in range(self.n_mappers):
167 temp_map_file = open(settings.get_temp_map_file(mapper_index, index), "r")
168 mapper_results = json.load(temp_map_file)
169 for (key, value) in mapper_results:
170 if not(key in key_values_map):
171 key_values_map[key] = []
172 try:
173 key_values_map[key].append(value)
174 except Exception, e:
175 print "Exception while inserting key: "+str(e)
176 temp_map_file.close()
177 if self.clean:
178 os.unlink(settings.get_temp_map_file(mapper_index, index))
179 key_value_list = []
180 for key in key_values_map:
181 key_value_list.append(self.reducer(key, key_values_map[key]))
182 output_file = open(settings.get_output_file(index), "w+")
183 json.dump(key_value_list, output_file)
184 output_file.close()
185
186 def run(self, join=False):
187 """Executes the map and reduce operations
188 :param join: True if we need to join the outputs, False by default.
189 """
190 # initialize mappers list
191 map_workers = []
192 # initialize reducers list
193 rdc_workers = []
194 # run the map step
195 for thread_id in range(self.n_mappers):
196 p = Process(target=self.run_mapper, args=(thread_id,))
197 p.start()
198 map_workers.append(p)
199 [t.join() for t in map_workers]
200 # run the reduce step
201 for thread_id in range(self.n_reducers):
202 p = Process(target=self.run_reducer, args=(thread_id,))
203 p.start()
204 map_workers.append(p)
205 [t.join() for t in rdc_workers]
206 if join:
207 self.join_outputs()
208
209 def join_outputs(self, clean = True, sort = True, decreasing = True):
210 """Join all the reduce output files into a single output file.
211
212 :param clean: if True the reduce outputs will be deleted, by default takes the value of self.clean
213 :param sort: sort the outputs
214 :param decreasing: sort by decreasing order, high value to low value
215
216 """
217 try:
218 return self.file_handler.join_files(self.n_reducers, clean, sort, decreasing)
219 except Exception, e:
220 print "Exception occured while joining: maybe the join has been performed already -- "+str(e)
221 return []ماژول Settings
این ماژول حاوی تنظیمات و تابعهای مفید پیشفرض برای ساخت نامهای مسیر برای ورودی، خروجی و فایلهای موقت است.
این متدهای کارآمد در قسمت «توضیحات» (comment) قطعه کد زیر شرح داده شدهاند.
1# set default directory for the input files
2default_input_dir = "input_files"
3# set default directory for the temporary map files
4default_map_dir = "temp_map_files"
5# set default directory for the output files
6default_output_dir = "output_files"
7# set default number for the map and reduce threads
8default_n_mappers = 4
9default_n_reducers = 4
10# return the name of the input file to be split into chunks
11def get_input_file(input_dir = None, extension = ".ext"):
12 if not(input_dir is None):
13 return input_dir+"/file" + extension
14 return default_input_dir + "/file" + extension
15
16
17# return the name of the current split file corresponding to the given index
18def get_input_split_file(index, input_dir = None, extension = ".ext"):
19 if not(input_dir is None):
20 return input_dir+"/file_"+ str(index) + extension
21 return default_input_dir + "/file_" + str(index) + extension
22
23
24# return the name of the temporary map file corresponding to the given index
25def get_temp_map_file(index, reducer, output_dir = None, extension = ".ext"):
26 if not(output_dir is None):
27 return output_dir + "/map_file_" + str(index)+"-" + str(reducer) + extension
28 return default_output_dir + "/map_file_" + str(index) + "-" + str(reducer) + extension
29
30# return the name of the output file given its corresponding index
31def get_output_file(index, output_dir = None, extension = ".out"):
32 if not(output_dir is None):
33 return output_dir+"/reduce_file_"+ str(index) + extension
34 return default_output_dir + "/reduce_file_" + str(index) + extension
35
36# return the name of the output file
37def get_output_join_file(output_dir = None, extension = ".out"):
38 if not(output_dir is None):
39 return output_dir +"/output" + extension
40 return default_output_dir + "/output" + extensionمثال شمارنده کلمات
در این مثال، فرض میشود که یک سند وجود دارد و هدف، شمردن تعداد وقوع هر کلمه در آن است. برای انجام این کار، نیاز به تعریف عملیات نگاشت و کاهش است تا بتوان متدهای mapper و reducer از کلاس MapReduce را پیادهسازی کرد.

راهکار برای شمارش کلمات، خیلی ساده است:
map: متن تقسیم میشود، سپس کلماتی که فقط حاوی کاراکترهای ascii و حروف کوچک هستند شمارش میشوند. پس از آن، هر کلمه به عنوان کلیدی با شمار ۱ ارسال میشود.
reduce: به سادگی میتوان همه مقادیر پیشین برای هر کلمه را جمع کرد.
بنابراین، کلاس MapReduce به صورت زیر پیادهسازی میشود.
1from mapreduce import MapReduce
2import sys
3class WordCount(MapReduce):
4 def __init__(self, input_dir, output_dir, n_mappers, n_reducers):
5 MapReduce.__init__(self, input_dir, output_dir, n_mappers, n_reducers)
6 def mapper(self, key, value):
7 """Map function for the word count example
8 Note: Each line needs to be separated into words, and each word
9 needs to be converted to lower case.
10 """
11 results = []
12 default_count = 1
13 # seperate line into words
14 for word in value.split():
15 if self.is_valid_word(word):
16 # lowercase wordsاگر نوشته بالا برای شما مفید بوده است، آموزشهای زیر نیز به شما پیشنهاد میشوند:
- مجموعه آموزشهای دادهکاوی و یادگیری ماشین
- مجموعه آموزش های داده کاوی یا Data Mining در متلب
- مجموعه آموزشهای آمار و احتمالات
- مفاهیم کلان داده (Big Data) و انواع تحلیل داده — راهنمای جامع
- کلان داده یا مِه داده (Big Data) — از صفر تا صد
- تحلیل کلان داده (Big Data)، چالش ها و فناوری های مرتبط — راهنما به زبان ساده
^^










