نمایش ناهنجاری و الگوریتم جنگل ایزوله با پایتون | راهنمای کاربردی
صعود و فرودهای ناگهانی برای یک اندازه یا متغیر نشانگر ناهنجاری یا رفتار نامتعارف برای یک پدیده است. نقاط فرورفتگی و هم برجستگیها نیز در نمودار مربوط به تغییرات یک پدیده در زمان، نشانگر وجود نقاط پرت یا دورافتاده است. اگر ما قبل از مدلسازی اطلاعاتی در مورد رفتار غیرعادی یک متغیر داشته باشیم، میتوان با اجرای «الگوریتمهای یادگیری نظارتی» (Supervised Learning Algorithms) مشکل وجود ناهنجاری را حل کرد، اما متاسفانه در ابتدا امر و زمانی که با دادهها مواجه هستیم، تشخیص آنها کار دشواری است. این مشکل ممکن است به نارسایی در مدل بیانجامد. به همین دلیل نمایش و شناسایی ناهنجاری قبل از مدل سازی روی دادهها امری ضروری است. در ادامه به کمک محاسبات و ترسیم نمودارهایی، قصد داریم از زبان پایتون و کتابخانههای آن برای نمایش ناهنجاری با الگوریتم جنگل ایزوله استفاده کنیم.
یکی از الگوریتمهای محبوب و البته کارا در زمینه شناسایی نقاط ناهنجار، «الگوریتم جنگل ایزوله» (Isolation Forest Algorithm) است. به منظور آشنایی با این الگوریتم بهتر است ابتدا نوشتارهای دیگر مجله فرادرس مانند الگوریتم جنگل ایزوله — راهنمای کاربردی و تشخیص ناهنجاری (Anomaly Detection) — به زبان ساده را مطالعه کنید. همچنین خواندن نوشتارهای الگوریتم جنگل ایزوله در پایتون — راهنمای کاربردی و مشاهده ناهنجار و شناسایی آن در SPSS — راهنمای کاربردی نیز خالی از لطف نیست.
نمایش ناهنجاری و الگوریتم جنگل ایزوله
همانطور که گفته شد، الگوریتمهای یادگیری نظارت شده به سختی قادر به نمایش ناهنجاری یا نقاط نامتعارف در دادهها هستند، زیرا نقاط از ابتدا به دو گروه هنجار و ناهنجار تفکیک یا افراز نشدهاند. در نتیجه «الگوریتمهای یادگیری غیرنظارتی» (Unsupervised Learning Algorithm) بخصوص روشهایی مانند «جنگل ایزوله» (Isolation Forest) که به اختصار IF نامیده شده همچنین تکنیک «ماشین بردار پشتیبان» (Support Vector Machine) که به اختصار SVM گفته میشوند، کارایی مناسبی دارند.

در ادامه به کمک ترسیم نمودارها و استفاده از الگوریتم IF سعی در شناسایی نقطههای ناهنجار در یک مجموعه داده خواهیم کرد. به این ترتیب یک محقق میتواند ناهنجاریها را در یک مجموعه داده تصادفی، تشخیص داده و با تحلیل نمودارها، چنین مشاهداتی را به طور مجزا و جداگانه مورد بررسی قرار میدهد. از طرفی او باید برای مدل سازی از مجموعه دادههای آموزشی بدون این نقطهها بهره ببرد.
بدون کمک بازخورد (Feedback)، تشخیص این گونه نقاط، کاری دشوار است. بنابراین ما با استفاده از الگوریتمهایی مانند Isolation Forest ، One class SVM و LSTM این مسئله را به عنوان یک مدل «غیرنظارتی» (Unsupervised Model) در نظر میگیریم. البته در ادامه این متن با استفاده از الگوریتم جنگل ایزوله یا IF، عمل خواهیم کرد.
اطلاعات مربوطه در اینجا برای هر مشاهده با ۱۲ متغیر (به عنوان مثال درآمد، ترافیک و غیره) مشخص میشوند. ابتدا باید تشخیص دهیم که آیا یک ناهنجاری در سطوح مختلف مشاهدات وجود دارد یا خیر. سپس برای عملکرد بهتر، به معیارها و ویژگیهای خاص مشاهدات به صورت جداگانه میپردازیم و ناهنجاریهای موجود در هر یک از متغیرها را شناسایی میکنیم.
کد زیر به منظور بارگذاری فایل داده و نصب کتابخانههای مورد نیاز در زبان برنامهنویسی پایتون نوشته شده است. توجه داشته باشید که دادههای به طور تصادفی ایجاد شده و در فایلی به نام metric_data.csv ذخیره شدهاند. شما نیز میتوانید چنین فایلی را به کمک توابع تصادفی در پایتون ایجاد کنید. البته توزیع تولید این دادهها به شکلی است که نقاط پرت تولید میشوند. در حقیقت بهتر است چنین دادههایی را از توزیعهای پایدار (Stable Distribution) با $$\alpha<2$$ تولید کنید.
1import numpy as np # linear algebra
2import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
3warnings.filterwarnings('ignore')
4import os
5print(os.listdir("../input"))
6df=pd.read_csv("../input/metric_data.csv")
7df.head()تصویر 1، نشانگر تعدادی از متغیرهای مربوطه برای مشاهدات اولیه این مجموعه داده (Dataframe) است.

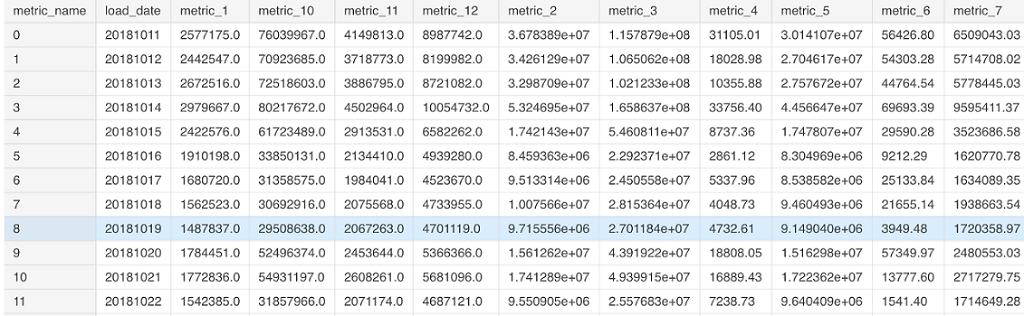
حالا یک تغییر محوری روی چارچوب داده، اجرا کرده و متغیرها را در سطوح مختلف مقادیر تاریخی ایجاد میکنیم. کد زیر به این منظور نوشته شده است.
1metrics_df=pd.pivot_table(df,values='actuals',index='load_date',columns='metric_name')
2metrics_df.reset_index(inplace=True)
3metrics_df.fillna(0,inplace=True)
4metrics_dfنتیجه اجرای این کد، تولید یک چارچوب داده جدید به اسم metrics_df است که در تصویر ۲، قسمتی از دادههای آن را مشاهده میکنید.
الگوریتم جنگل ایزوله سعی دارد نقاط ناهنجار را از این مجموعه داده استخراج کند. اگر هر متغیر (metric_i) را برحسب زمان ترسیم کنیم، یک نمودار خطی حاصل میشود که مطابق با آن رفتار و تغییرات متغیرها قابل مشاهده است. به این ترتیب نقطههایی که رفتار متفاوت با بقیه نقاط دارند شناسایی میشوند. در حقیقت این نقاط در قلهها یا فرورفتگیهای عمیق منحنی قرار خواهند گرفت. در مقابل نقاط هنجار در کنار یکدیگر بوده و روند کلی منحنی را نمایش میدهند. در ادامه به کدهایی اشاره خواهیم کرد که با استفاده از الگوریتم جنگل ایزوله، در کتابخانه sklearn نمایش ناهنجاری را به شکل جداگانه روی یک نمودار دو بعدی نمایش خواهد داد.
نکته: در اینجا برای هر متغیر به شکل مجزا، از الگوریتم جنگل ایزوله استفاده میکنیم. ولی الگوریتم بهینه شده h2o که برگرفته از IF است، قادر به محاسبات روی دادههای حجیم و با ابعاد بالا است که در نوشتارهای دیگر مجله فرادرس به آن نیز خواهیم پرداخت.
1metrics_df.columns
2#specify the 12 metrics column names to be modelled
3to_model_columns=metrics_df.columns[1:13]
4from sklearn.ensemble import IsolationForest
5clf=IsolationForest(n_estimators=100, max_samples='auto', contamination=float(.12), \
6 max_features=1.0, bootstrap=False, n_jobs=-1, random_state=42, verbose=0)
7clf.fit(metrics_df[to_model_columns])
8pred = clf.predict(metrics_df[to_model_columns])
9metrics_df['anomaly']=pred
10outliers=metrics_df.loc[metrics_df['anomaly']==-1]
11outlier_index=list(outliers.index)
12#print(outlier_index)
13#Find the number of anomalies and normal points here points classified -1 are anomalous
14print(metrics_df['anomaly'].value_counts())در تصویر زیر تعداد نقاط ناهنجار که با کد ۱- مشخص شدهاند، نمایش داده شده است.

کاهش ابعاد با تکنیک PCA
همانطور که میدانید، ۱۲ متغیر در چارچوب داده (DataFrame) وجود دارد. بنابراین باید بر حسب هر یک از آنها نقاط ناهنجار را مشخص کنیم. البته این کار با توجه به ابعاد مسئله و وجود همبستگی (Correlation) بین بعضی از متغیرها، ممکن است مشکلساز شود.

برای کاهش تعداد ابعاد، متغیرها را با تکنیک تحلیل مولفههای اصلی (PCA) تبدیل کرده و به مولفههایی با کمترین همبستگی و البته با بیشترین اطلاعات خواهیم رسید. در انتها نیز براساس سه مولفه اصلی که بیشترین توضیح برای دادهها خواهند بود، نموداری برای شناسایی نقاط ناهنجار معرفی شده توسط الگوریتم IF، ترسیم خواهیم کرد.
کدهایی مربوط به استخراج مولفههای PCA و رسم نمودار سه بعُدی در ادامه دیده میشود.
1import matplotlib.pyplot as plt
2from sklearn.decomposition import PCA
3from sklearn.preprocessing import StandardScaler
4from mpl_toolkits.mplot3d import Axes3D
5pca = PCA(n_components=3) # Reduce to k=3 dimensions
6scaler = StandardScaler()
7#normalize the metrics
8X = scaler.fit_transform(metrics_df[to_model_columns])
9X_reduce = pca.fit_transform(X)
10fig = plt.figure()
11ax = fig.add_subplot(111, projection='3d')
12ax.set_zlabel("x_composite_3")
13# Plot the compressed data points
14ax.scatter(X_reduce[:, 0], X_reduce[:, 1], zs=X_reduce[:, 2], s=4, lw=1, label="inliers",c="green")
15# Plot x's for the ground truth outliers
16ax.scatter(X_reduce[outlier_index,0],X_reduce[outlier_index,1], X_reduce[outlier_index,2],
17 lw=2, s=60, marker="x", c="red", label="outliers")
18ax.legend()
19plt.show()
حالا همانطور که در نمودار مربوط به تصویر ۴، مشاهده میکنیم، نقاط ناهنجار با نقاط هنجار، که به صورت یک خوشه متمرکز در نمودار دیده میشوند، فاصله زیادی دارند. از طرفی نمودار دو بُعدی نیز به ما کمک میکند که نمایش ناهنجاری را بهتر کرده و دقیقتر قضاوت کنیم. اجازه دهید نمودار را برای حالت دو بُعدی برای دو مولفه دوم ترسیم کنیم.
کدی که در ادامه مشاهده میکنید به این منظور نوشته شده. همانطور که مشاهده میکنید، تعداد مولفهها را برابر با دو در نظر گرفته و به صورت (PCA(2 مشخص شده است.
1from sklearn.decomposition import PCA
2pca = PCA(2)
3pca.fit(metrics_df[to_model_columns])
4res=pd.DataFrame(pca.transform(metrics_df[to_model_columns]))
5Z = np.array(res)
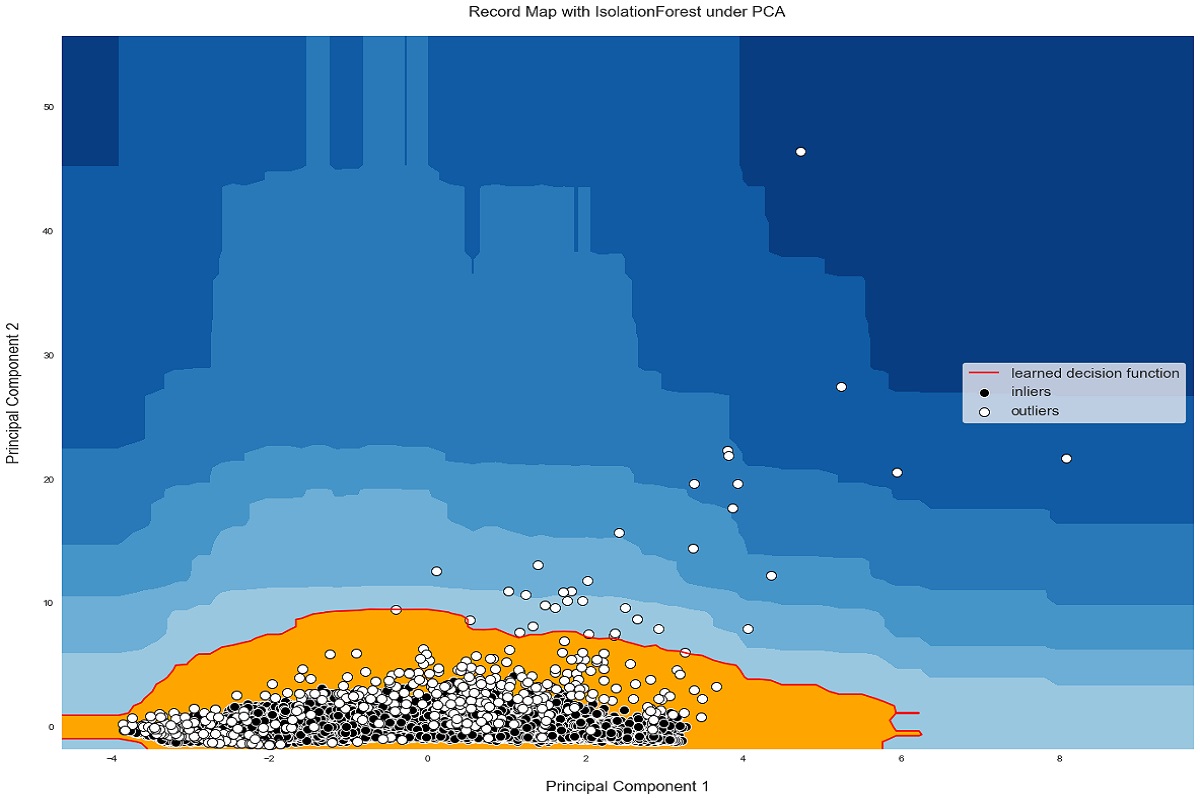
6plt.title("IsolationForest")
7plt.contourf( Z, cmap=plt.cm.Blues_r)
8b1 = plt.scatter(res[0], res[1], c='green',
9 s=20,label="normal points")
10b1 =plt.scatter(res.iloc[outlier_index,0],res.iloc[outlier_index,1], c='green',s=20, edgecolor="red",label="predicted outliers")
11plt.legend(loc="upper right")
12plt.show()نتیجه اجرای این کد، رسم نموداری است که در تصویر 5، قابل مشاهده است.

بنابراین یک نقشه 2D تصویر روشنی را به ما میدهد که الگوریتم نقاط ناهنجاری موجود را به درستی طبقهبندی کرده است. نمایش ناهنجاری به صورت نقاط قرمز رنگ در نمودار، برجسته شده و نقاط عادی با دایرههای سبز رنگ در این نمودار نمایان گردیده است.
نمایش ناهنجاری دو بعدی
اکنون ما رفتار نقاط ناهنجار را در هر یک از مولفهها شناختهایم و این راهکاری برای پیدا کردن مشاهدات ناهنجار است. نقاط ناهنجاری مشخص شده توسط الگوریتم، باید هنگام رسم نمودار دو بعُدی براساس متغیرها (Metrics) به صورت نقاط قلهها یا درهها دیده شوند که بیانگر پرش یا افت ناگهانی متغیرها است.

به منظور ترسیم نمودارهایی که این رفتارها را نشان دهند، کدهای زیر را تهیه کردهایم. در این جا هر یک از نقاط ناهنجار به همراه دیگر مشاهدات روی یک نمودار دو بُعدی ترسیم شده که محور افقی، زمان و محور عمودی، مقدار متغیر (Metric) است.
1from plotly.offline import download_plotlyjs, init_notebook_mode, plot, iplot
2import plotly.plotly as py
3import matplotlib.pyplot as plt
4from matplotlib import pyplot
5import plotly.graph_objs as go
6init_notebook_mode(connected=True)
7def plot_anomaly(df,metric_name):
8 df.load_date = pd.to_datetime(df['load_date'].astype(str), format="%Y%m%d")
9 dates = df.load_date
10 #identify the anomaly points and create a array of its values for plot
11 bool_array = (abs(df['anomaly']) > 0)
12 actuals = df["actuals"][-len(bool_array):]
13 anomaly_points = bool_array * actuals
14 anomaly_points[anomaly_points == 0] = np.nan
15 #A dictionary for conditional format table based on anomaly
16 color_map = {0: "'rgba(228, 222, 249, 0.65)'", 1: "yellow", 2: "red"}
17
18 #Table which includes Date,Actuals,Change occured from previous point
19 table = go.Table(
20 domain=dict(x=[0, 1],
21 y=[0, 0.3]),
22 columnwidth=[1, 2],
23 # columnorder=[0, 1, 2,],
24 header=dict(height=20,
25 values=[['<b>Date</b>'], ['<b>Actual Values </b>'], ['<b>% Change </b>'],
26 ],
27 font=dict(color=['rgb(45, 45, 45)'] * 5, size=14),
28 fill=dict(color='#d562be')),
29 cells=dict(values=[df.round(3)[k].tolist() for k in ['load_date', 'actuals', 'percentage_change']],
30 line=dict(color='#506784'),
31 align=['center'] * 5,
32 font=dict(color=['rgb(40, 40, 40)'] * 5, size=12),
33 # format = [None] + [",.4f"] + [',.4f'],
34 # suffix=[None] * 4,
35 suffix=[None] + [''] + [''] + ['%'] + [''],
36 height=27,
37 fill=dict(color=[test_df['anomaly_class'].map(color_map)],#map based on anomaly level from dictionary
38 )
39 ))
40 #Plot the actuals points
41 Actuals = go.Scatter(name='Actuals',
42 x=dates,
43 y=df['actuals'],
44 xaxis='x1', yaxis='y1',
45 mode='line',
46 marker=dict(size=12,
47 line=dict(width=1),
48 color="blue"))
49#Highlight the anomaly points
50 anomalies_map = go.Scatter(name="Anomaly",
51 showlegend=True,
52 x=dates,
53 y=anomaly_points,
54 mode='markers',
55 xaxis='x1',
56 yaxis='y1',
57 marker=dict(color="red",
58 size=11,
59 line=dict(
60 color="red",
61 width=2)))
62axis = dict(
63 showline=True,
64 zeroline=False,
65 showgrid=True,
66 mirror=True,
67 ticklen=4,
68 gridcolor='#ffffff',
69 tickfont=dict(size=10))
70layout = dict(
71 width=1000,
72 height=865,
73 autosize=False,
74 title=metric_name,
75 margin=dict(t=75),
76 showlegend=True,
77 xaxis1=dict(axis, **dict(domain=[0, 1], anchor='y1', showticklabels=True)),
78 yaxis1=dict(axis, **dict(domain=[2 * 0.21 + 0.20, 1], anchor='x1', hoverformat='.2f')))
79fig = go.Figure(data=[table, anomalies_map, Actuals], layout=layout)
80iplot(fig)
81pyplot.show()البته از آنجایی که دادهها چند بعُدی هستند، نمیتوان تنها به این نمودارها اکتفا کنیم. همانطور که در ابتدای متن خواندید، برای کاهش ابعاد از روش PCA استفاده کرده و براساس آنها نقاط ناهنجار را شناسایی کردیم. نمودارهای دو بعُدی ترسیم شده، نقش راهنما و یا تایید نتایج حاصل از اجرای الگوریتم IF را برای نمایش ناهنجاری دارند.
کد زیر به منظور دستهبندی متغیرها و نقش آنها در تعیین نقطه ناهنجار نوشته شده است. همچنین نقطهها براساس میزان ناهنجاری به سه دسته ۰- بدون ناهنجاری، ۱- ناهنجاری کم و ۲-ناهنجاری زیاد، طبقهبندی میشوند.
1def classify_anomalies(df,metric_name):
2 df['metric_name']=metric_name
3 df = df.sort_values(by='load_date', ascending=False)
4 #Shift actuals by one timestamp to find the percentage change between current and previous data point
5 df['shift'] = df['actuals'].shift(-1)
6 df['percentage_change'] = ((df['actuals'] - df['shift']) / df['actuals']) * 100
7 #Categorise anomalies as 0-no anomaly, 1- low anomaly , 2 - high anomaly
8 df['anomaly'].loc[df['anomaly'] == 1] = 0
9 df['anomaly'].loc[df['anomaly'] == -1] = 2
10 df['anomaly_class'] = df['anomaly']
11 max_anomaly_score = df['score'].loc[df['anomaly_class'] == 2].max()
12 medium_percentile = df['score'].quantile(0.24)
13 df['anomaly_class'].loc[(df['score'] > max_anomaly_score) & (df['score'] <= medium_percentile)] = 1
14 return dfهمانطور که در تصویر ۶، مشخص است محور X - تاریخ و محور Y - مقادیر واقعی و نقاط قرمز نیز ناهنجاری را مشخص کردهاند. مقادیر واقعی با خطوط آبی و نقاط ناهنجار با دایرههای قرمز رنگ در نمودار نسبت به دیگر نقاط، متمایز شدهاند.
1import warnings
2warnings.filterwarnings('ignore')
3for i in range(1,len(metrics_df.columns)-1):
4 clf.fit(metrics_df.iloc[:,i:i+1])
5 pred = clf.predict(metrics_df.iloc[:,i:i+1])
6 test_df=pd.DataFrame()
7 test_df['load_date']=metrics_df['load_date']
8 #Find decision function to find the score and classify anomalies
9 test_df['score']=clf.decision_function(metrics_df.iloc[:,i:i+1])
10 test_df['actuals']=metrics_df.iloc[:,i:i+1]
11 test_df['anomaly']=pred
12 #Get the indexes of outliers in order to compare the metrics with use case anomalies if required
13 outliers=test_df.loc[test_df['anomaly']==-1]
14 outlier_index=list(outliers.index)
15 test_df=classify_anomalies(test_df,metrics_df.columns[i])
16 plot_anomaly(test_df,metrics_df.columns[i])
در تصویر شماره ۷، نمایش ناهنجاری را به کمک متغیر 10_metric مشخص کردهایم. از آنجایی که هر دو این متغیرها در راستای یکدیگر تغییر میکنند، نقاط ناهنجار یکسانی را معرفی میکنند.

همانطور که دیده میشود، به کمک نمودارهای ترسیم شده، قلهها و فرورفتگیهای ناگهانی در هر یک از شاخصها، معرف نقاط ناهنجار خواهند بود. خوشبختانه، الگوریتم جنگل ایزوله نیز این نقاط را به درستی شناسایی کرده است.
خلاصه و جمعبندی
جنگل ایزوله یا جنگل جداسازی یک الگوریتم یا تکنیک تشخیص فاصله است که به جای مشاهدات عادی، بر ناهنجاریها تکیه دارد. الگوریتم جنگل ایزوله درست به مانند روشی که در جستجوی درخت باینری عمل میشود، وظیفه شناسایی نقاط یا نمایش ناهنجاری ها را انجام میدهد. در این نوشتار الگوریتم جنگل ایزوله در پایتون پیادهسازی شد و کارایی و قابلیتهای آن نیز به کمک مثالی با دادههای تصادفی مورد بررسی قرار گرفت. به منظور درک بهتر الگوریتم و نحوه جداسازی نقاط ناهنجار، از نمودارهایی در این زمینه استفاده کردیم.

در بیشتر الگوریتمها موجود در این زمینه، ویژگیهای دادههای متعارف و هنجار مشخص شده، سپس با توجه به تابع فاصله در نظر گرفته شده، نقاط ناهنجار و دورافتاده نسبت به آنها شناسایی میشوند. در حالیکه مطابق با الگوی به کار رفته در الگوریتم جنگل ایزوله، از همان ابتدا، هدف جداسازی و نمایش ناهنجاری است. به همین علت، دقت و البته سرعت اجرای الگوریتم جداسازی یا ایزوله کردن نقاط ناهنجار بسیار بیشتر است. همین امر نقطه قوت این الگوریتم در شناسایی نقطهها یا مشاهدات ناهنجار یا دورافتاده محسوب میشود.










