جمع بندی داده در SPSS — راهنمای کاربردی

یکی از شیوههای خلاصهسازی دادهها در محاسبات آماری، جمعبندی (Aggregate) است که به عنوان یکی از گامهای دادهکاوی در بخش پیشپردازش دادهها به کار میرود. برای مثال میانگینگیری یا محاسبه حاصل جمع یک متغیر، جمعبندی محسوب میشود. البته میتوان این جمعبندی را به تفکیک یک یا چند متغیر دیگر نیز انجام داد. برای مثال محاسبه میانگین حقوق افراد برحسب محل خدمتشان نوعی جمعبندی است. در این نوشتار با جمع بندی داده در SPSS آشنا خواهیم شد و براساس مثالهایی، این موضوع را عمیقتر مورد بررسی قرار خواهیم داد.
برای آشنایی بیشتر با محاسبات آماری در نسخههای جدید نرمافزار SPSS بهتر است مطلب امکانات جدید SPSS نسخه ۲۵ که باید آنها را بدانید را مطالعه کنید. همچنین اگر میخواهید با محیط SPSS و نحوه به کارگیری پنجرههای آن بیشتر آشنا شوید خواندن نوشتار پنجره ویرایشگر داده (Data Editor) در SPSS — راهنمای کاربردی نیز خالی از لطف نیست.
جمع بندی داده در SPSS
در تهیه گزارشات آماری، اغلب با مسئله جمعبندی مواجه هستیم زیرا هدف از تهیه گزارشات مالی و مدیریت یا عملکردی، ارائه اطلاعات فشرده شده از همه دادهها است. این فشردهسازی باید به شکلی صورت گیرد که از گزارشات ایجاد شده، بیشترین اطلاعات را کسب کرد. جمعبندی دادهها یکی از روشهایی است که اختصاص به انجام این عمل دارد. از طرفی ممکن است بخواهیم برای بعضی از گروهها یا دستهها، جمعبندی را انجام دهیم. از آنجایی که SPSS به عنوان یکی از نرمافزارهای کاربردی مناسب برای انجام تحلیل آماری است، در این نوشتار نحوه جمع بندی داده در SPSS را فرا خواهیم گرفت. برای روشن شدن موضوع نیز با استفاده از یک منبع داده و پرسشهایی که میتوانند به عنوان گزارشات در نظر گرفته شوند، مثالهایی مطرح خواهیم کرد.

برای مثال فرض کنید شما یک فروشگاه بزرگ دارید که به فروش چند کالای خاص اختصاص دادهاید. در این فروشگاه یک نوع کالا را از دو تولید کننده متفاوت عرضه میکنید. ممکن است لازم باشد مجموع فروش این کالا را به تفکیک شرکت تولید کننده محاسبه کنید تا با سلیقه مشتریانتان بیشتر آشنا شوید. این عمل نیز نوعی جمعبندی روی میزان فروش کالا است که براساس نام تولید کننده، تفکیک شده است.
از طرفی، شیفت کاری نیز در فروشگاه، وجود دارد و میخواهید کارایی هر شیفت را نیز بسنجید. همچنین ممکن است بین شیفت کاری و شرکت تولید کننده نیز رابطه برقرار باشد. به این معنی که مشتریان صبحها به محصول مثلا نوع یک بیشتر تمایل دارند و در شیفت شب، فروش محصول نوع دو بیشتر است. براساس نتایج محاسبات به کمک جمعبندی روی دادهها، این اطلاعات و گزارشات را میتوان بدست آورد.
به این ترتیب ممکن است شاخصهای حاصل از جمعبندی به تنهایی یا براساس یک یا چند متغیر تفکیکی (Categorical Variable)، محاسبه و به کار گرفته شوند. در ادامه با نحوه انجام این گونه محاسبات در SPSS آشنا خواهیم شد و به کمک دستورات متنوعی، عملیات جمع بندی داده در SPSS را اجرا خواهیم کرد.
ابتدا با یک مجموعه داده در SPSS آشنا میشویم که در ادامه کار، از آن در قالب مثالهایی استفاده خواهیم کرد. این مجموعه داده، دارای چهار متغیر و شامل ۱۲ مشاهده بوده که هر سطر مربوط به مقادیر اندازهگیری شده در یک ماه است. این متغیرها به ترتیب میزان سفارش (Purchase)، میزان فروش (Sale)، نوع کالا (Type) و شیفت کاری (Group) هستند. متغیر اول و دوم، از نوع مقیاس (Scale) و کمّی هستند و متغیرهای سوم و چهارم نیز از نوع اسمی (Nominal) محسوب میشوند. متغیر نوع کالا دارای دو سطح (نوع یک و نوع دو) بوده و متغیر شیفت کاری نیز دارای سه سطح (شیفت صبح، عصر و شب) است. واضح است که در اغلب موارد از متغیرهای اسمی (کیفی) برای طبقهبندی کردن مجموعه داده، استفاده میشود و برای جمعبندی از متغیرهای مقیاس (کمی) کمک میگیریم. به منظور راحتی در اجرای عملیاتی که در این نوشتار به آنها اشاره کردهایم، فایل اطلاعاتی این مجموعه داده با نام aggregate.sav را میتوانید از اینجا با قالب فشرده (Zip) دریافت کنید.
تصویر ۱ این مجموعه داده را نشان داده و در تصویر ۲ نیز نحوه تعریف این متغیرها در این فایل داده، دیده میشود.


در تصویر ۲، برچسب هر یک از متغیرها در ستون Label مشخص و همچنین برچسب مقادیر نیز در ستون Values برای متغیرهای type و group تعیین شده است.
فرض کنید قرار است به پرسشهای زیر در رابطه با مجموعه داده مطرح شده، پاسخ دهیم.
- میانگین و انحراف معیار میزان فروش (Sale) چقدر است؟
- در چند ماه از ماههای سال، فروش کالا از میانگین فروش سالانه کمتر بوده است؟
- جمع فروش و میزان سفارش کالا به تفکیک نوع کالا، چقدر است؟
- حداکثر و حداقل فروش و سفارش برای هر نوع کالا در طول سال به چه میزان است؟
- حداکثر و حداقل فروش و سفارش برای هر نوع کالا در طول سال به تفکیک شیفت کاری چه میزان است؟
در ادامه به هر یک از این پرسشها با دستورات مختلفی از SPSS، پاسخ خواهیم داد و ابتدا از دستور Aggregate کمک میگیریم.
جمع بندی داده در SPSS با دستور Aggregate
یکی از روشهای محاسبات برمبنای جمع بندی در SPSS استفاده از دستور Aggregate است. بعضی از شاخصهای آماری مهم مانند میانگین، میانه و انحراف معیار به همراه چندکها (چارک، دهک یا صدک) توسط این دستور قابل محاسبه هستند. به منظور دسترسی به این دستور، کافی است از فهرست Data دستور Aggregate را اجرا کنید. دقت داشته باشید که خروجی این دستور یک یا چند متغیر جدید است که مقادیر حاصل از جمعبندی را در خود جای میدهند. در تصویر ۳، برخی از این شاخصها دیده میشوند. جدولهای ۱ تا ۳ نیز به معرفی عملکرد توابعی که توسط دستور Aggregate قابل محاسبه هستند، پرداخته است.

ابتدا بهتر است با پنجره دستور Aggregate بیشتر آشنا شویم.
پارامترها و تنظیمات دستور Aggregate
در تصویر زیر پنجره جمعبندی (Aggregate) دیده میشود. همانطور که در دیگر پنجرههای SPSS نیز دیده میشود، کادر سمت چپ، مربوط به اسامی متغیرهایی است که میتوانیم در این تحلیل از آنها استفاده کنیم. در ادامه قسمتهای مختلف این پنجره معرفی شدهاند.
- کادر Break Variables، محل قرارگیری متغیرهایی است که باعث طبقهبندی یا دستهبندی مشاهدات مجموعه داده میشوند. برای مثال متغیرهای نوع کالا یا شیفت کاری میتوانند در این کادر قرار گیرند تا به این وسیله امکان جمعبندی روی میزان سفارش یا مبلغ فروش به تفکیک آنها صورت گیرد.
- در بخش Aggregate Variables و کادر (Summaries of Variables(s، متغیرهایی که برای جمعبندی لازم هستند، قرار میگیرند. اغلب این متغیرها از نوع کمی هستند البته میتوانید متغیرهای کیفی مثلا از نوع اسمی (Nominal) یا ترتیبی (Ordinal) را نیز در آن قرار دهید ولی دیگر انتظار نداشته باشید که میانگین یا انحراف معیار برای آنها معنی دار باشد. در این گونه مواقع بهتر است شمارش مشاهدات یا درصدگیری را انجام دهید.

با استفاده از دکمه Function، نوع محاسبهای که در جمعبندی به کار میرود انتخاب میشود.

این محاسبات برای متغیرهای کمی در قسمت Summary Statistics ظاهر شده است. جدول زیر این گزینهها را معرفی کرده است.
جدول ۱: توابع دستور Aggregate برای دادههای کمی (مقیاس-Scale)
| نام تابع | نوع محاسبه |
| Mean | میانگین |
| Median | میانه |
| Sum | مجموع |
| Standard Deviation | انحراف استاندارد |
همچنین برای متغیرهای ترتیبی یا کمی از لیست Specific Values نیز میتوانید استفاده کنید. ضمناً برای متغیرهای اسمی، بهتر است شمارش مشاهدات که در قسمت Number of cases قرار گرفتهاند را انتخاب کنید. در جدول ۲ و ۳ گزینههای مربوطه، مشخص شدهاند.
جدول ۲: توابع دستور Aggregate برای دادههای ترتیبی و کمی (مقیاس-Scale)
| نام | مقدار |
| First | اولین مقدار |
| Last | آخرین مقدار |
| Minimum | کوچکترین مقدار |
| Maximum | بزرگترین مقدار |
اگر بوسیله دستور Weight Cases از فهرست Data، مشاهدات را وزندار کردهاید، گزینههای قسمت Number of cases ممکن است خروجیهای متفاوتی ظاهر کنند.
جدول ۳: توابع دستور Aggregate برای دادههای اسمی، ترتیبی و کمی (مقیاس-Scale)
| نام | شرح |
| Weighted | استفاده از متغیر وزندهی هنگام شمارش مشاهدات |
| Weighted missing | استفاده از متغیر وزندهی و نمایش مشاهدات با مقادیر گمشده |
| Unweighted | بدون استفاده از متغیر وزندهی و شمارش مشاهدات طبق جدول اطلاعاتی |
| Unweighted missing | بدون استفاده از متغیر وزندهی و شمارش همه مشاهدات حتی با مقدار گمشده طبق جدول اطلاعاتی |
از طرفی در قسمت Percentage, Fractions, Counts میتوانید، مشاهدات را شمارش (Counts) کرده یا نسبتی (Fraction) از آنها را به عنوان یک متغیر جدید محاسبه کنید. حتی درصد خاصی از آنها را (مثلا درصد مشاهداتی که مقدار فروش آنها بیشتر از ۱۵۰ است) را به کمک Percentages تحت عنوان یک متغیر جدید ظاهر کنید.
با انتخاب دکمه Name and Label پنجرهای مانند تصویر زیر ظاهر شده که در آن میتوانید برای متغیرهای جدید که توسط جمعبندی ایجاد میکنید نام یا برچسب تعیین کنید.

در تصویر زیر، تنظیماتی از پنجره Aggregate را میبینید که مربوط به نحوه ذخیره سازی نتایج اجرای جمعبندی است.

- گزینه ...Add aggregate variable باعث میشود که نتیجه جمعبندی به عنوان متغیرهایی به مجموعه داده فعال (active dataset) اضافه شود.
- با انتخاب گزینه ...Create a new dataset، متغیرهای نتیجه جمعبندی، در یک مجموعه داده جدید ثبت میشود. نام این مجموعه داده باید در قسمت Dataset name مشخص شود.
- اگر گزینه ...Write a new انتخاب شود، نتیجه جمعبندی در یک فایل اطلاعاتی جدید ثبت میشود.
- در قسمت Options for Very Large Datasets میتوانید گزینههایی که برای کار با مجموعه داده بزرگ است را انتخاب یا تغییر دهید. اگر مجموعه داده براساس متغیرهایی طبقهای مرتب شده است گزینه اول را انتخاب کنید. ولی اگر میخواهید به محاسبات خود سرعت بیشتری بدهید بهتر است با انتخاب Sort file before aggregating، مجموعه داده را برحسب متغیرهای طبقهای مرتب کنید.
با فشردن دکمه Continue به پنجره اولیه باز خواهید گشت. بعد از همه این تنظیمات، با زدن دکمه OK، متغیر حاصل از جمعبندی در پنجره Data Editor و در برگه Data View قابل مشاهده است. حال سوالاتی که برای مجموعه داده aggregate.sav مطرح شد را پاسخ میدهیم.
سوال ۱: میانگین و انحراف معیار میزان فروش (Sale) چقدر است؟

پاسخ سوال ۱: همانطور که دیده میشود، با قرار دادن متغیر فروش (Sale) و انتخاب تابع MEAN در پنجره Function، نوع محاسبات مشخص شده است. برای نمایش خروجی نیز از یک مجموعه داده جدید به نام mean استفاده شده است. اگر بخواهیم انحراف استاندارد را هم ثبت کنیم کافی است در پنجره Function نوع محاسبه را Standard deviation انتخاب کرده و عملیات را انجام دهیم.
سوال ۲: در چند ماه از ماههای سال، فروش کالا از میانگین فروش سالانه کمتر بوده است؟
پاسخ سوال ۲: با توجه به پاسخ سوال ۱، مشخص است که میانگین فروش سالانه برابر است با 146٫67. در نتیجه کافی است برای متغیر فروش (Sale) در پنجره Function تنظیم را به صورت زیر انجام دهیم.

به این ترتیب اگر در قسمت Save در پنجره اصلی گزینه ...Add را انتخاب کرده باشیم، نتیجه به صورت زیر خواهد بود.

سوال ۳: جمع فروش و میزان سفارش کالا به تفکیک نوع کالا، چقدر است؟

پاسخ سوال ۳: توجه داشته باشید که متغیر نوع کالا به عنوان متغیر طبقهای مورد استفاده قرار گرفته و تابع مورد محاسبه در پنجره Function، تابع SUM انتخاب شده است. نتیجه اجرای این دستور به صورت زیر خواهد بود.
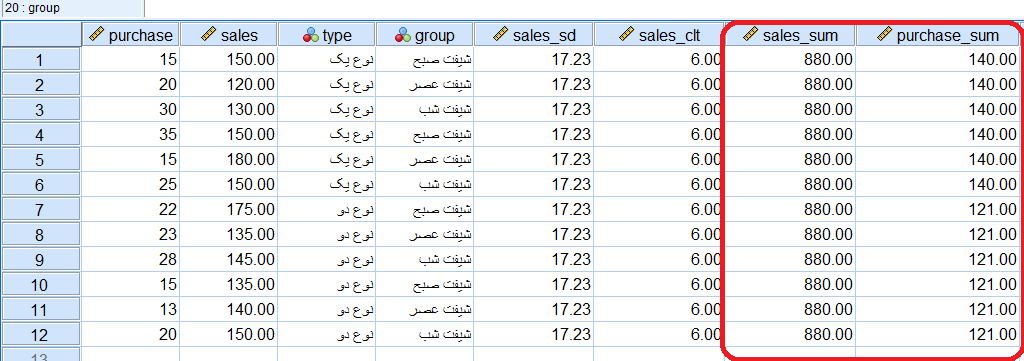
سوال ۴: حداکثر و حداقل فروش و سفارش برای هر نوع کالا در طول سال به چه میزان است؟
پاسخ سوال ۴: برای پاسخ به این سوال میتوانید به مانند روشی که در پاسخ سوال ۵ نیز گفته شده عمل کنید با این تفاوت که در قسمت Break Variable فقط از متغیر type به عنوان متغیر طبقهای استفاده کنید. در نتیجه به منظور صرفهجویی در فضای نوشتاری از نمایش تصویر این دستور صرفنظر کردهایم.
سوال ۵: حداکثر و حداقل فروش و سفارش برای هر نوع کالا در طول سال به تفکیک شیفتکاری چه میزان است؟
پاسخ سوال ۵: همانطور که در سوال مشخص است، برای پاسخ باید از دو متغیر طبقهای، استفاده شود. همچنین برای هر دو متغیرهای عددی فروش (Sale) و سفارش (Purchase)، دو شاخص حداقل و حداکثر مورد احتیاج است. اگر تنظیمات پنجره Aggregate را مطابق با تصویر زیر ایجاد کنید، نتیجه مورد نظر، حاصل خواهد شد.

همانطور که مشخص است، متغیرهای طبقهای نوع کالا (type) و شیفت کاری (group) در کادر Break Variable قرار گرفتهاند. همچنین برای محاسبه حداقل و حداکثر میزان فروش، دوبار متغیر sales به کادر Summaries of Variable وارد شده و برای هر کدام یکبار تابع MIN و یکبار هم تابع MAX به کار رفته است. همین عملیات نیز برای متغیر سفارش (Purchase) صورت گرفته. در قسمت Save نیز، انتخاب گزینه ...Write a new، باعث میشود که خروجی این دستور در قالب یک فایل اطلاعاتی جدید به نام aggr.sav ثبت شود.
اگر میخواهید با استفاده از محیط Syntax، دستورات مربوط به پاسخ سوال ۵ را انجام دهید باید برنامهای به شکل زیر را اجرا کنید.
1GET
2 FILE='C:\Users\a.reybod\Documents\blog\Aggregate data in SPSS\aggregate.sav'.
3DATASET NAME DataSet1 WINDOW=FRONT.
4AGGREGATE
5 /OUTFILE='C:\Users\a.reybod\Documents\blog\Aggregate data in SPSS\aggr.sav'
6 /BREAK=type group
7 /sales_min=MIN(sales)
8 /sales_max=MAX(sales)
9 /purchase_min=MIN(purchase)
10 /purchase_max=MAX(purchase).نکته: همانطور که مشاهده کردید، دستور Aggregate باعث بوجود آمدن یک متغیر جدید، براساس جمعبندی روی مشاهدات میشود ولی نتیجه این محاسبات در خروجی SPSS ظاهر نمیشود. اگر میخواهید به جای متغیر جمع بندی در SPSS نتایج را به عنوان یک گزارش مشاهده کنید از دستوراتی که در ادامه معرفی میشوند، استفاده کنید.
جمع بندی داده در SPSS با دستور OLAP Cube
OLAP Cube یا «مکعبهای پردازش تحلیلی برخط» (Online Analytical Processing)، ابزاری برای جمع بندی داده در SPSS محسوب میشوند که درست به مانند جداول محوری (Pivotal Table) عمل میکنند و براساس آنها میتوان خروجیهای متنوع و کاملی دریافت کرد.

اغلب از ابزار OLAP، برای تهیه جدولهای فراوانی یک یا دو طرفه و همچنین محاسبه شاخصهای آماری براساس یک یا چند متغیر طبقهای کمک گرفته میشود.

نکته: در تحلیل OLAP باید حتما در کادرهای اول و دوم این پنجره، متغیری معرفی شود، در غیر این صورت امکان انجام تحلیل وجود ندارد. از مزایای استفاده از OLAP، امکان بهرهگیری از فیلتر در خروجیها است که باعث میشود، نتایج بنا به انتخاب شما، محاسبه و نمایش داده شوند.
در تصویر زیر، شاخصهای محاسباتی زیادی دیده میشوند که توسط دستور OLAP قابل اجرا هستند. بیشتر شاخصهای آماری نظیر، میانگین، انحراف معیار، واریانس و حتی چولگی و برجستگی در این لیست دیده میشوند.

اگر در پنجره OLAP Cubes گزینه Differences را انتخاب کنید، پنجرهای به شکل زیر ظاهر شده که در آن میتوانید برمبنای اختلافات بین متغیرها (Difference between variables) یا اختلاف بین گروهها (Differences between groups) اختلاف شاخصهای محاسباتی را بدست آورید.

نکته: اختلاف را میتوان براساس اختلاف درصدی (Percentage difference) یا اختلاف ریاضیاتی (Arithmetic difference) در نظر گرفت.
برای پاسخ به سوالات گفته شده، تصویرهای که مربوط به دستور و تنظیمات پنجره OLAP Cubes است، در ادامه گنجانده شدهاند.
سوال ۱: میانگین و انحراف معیار میزان فروش (Sale) چقدر است؟
پاسخ سوال ۱: با توجه به نکته ذکر شده در بخش OLAP Cubes، امکان پاسخ به این سوال وجود ندارد؛ زیرا حتما باید یک متغیر طبقهای برای انجام محاسبات منظور شود.
سوال ۲: در چند ماه از ماههای سال، فروش کالا از میانگین فروش سالانه کمتر بوده است؟
پاسخ سوال ۲: متاسفانه پاسخ به این سوال نیز در حیطه عملیات مربوط به OLAP نیست.
سوال ۳: جمع فروش و میزان سفارش کالا به تفکیک نوع کالا، چقدر است؟
پاسخ سوال ۳: اگر تنظیمات پنجره OLAP را مطابق با تصویر زیر انجام دهیم، میتوانیم، خروجی مورد نظر را با توجه به گزینه انتخابی Sum در پنجره Statistics ایجاد کنیم.

در این صورت خروجی زیر حاصل خواهد شد.

سوال ۴: حداکثر و حداقل فروش و سفارش برای هر نوع کالا در طول سال به چه میزان است؟
پاسخ سوال ۴: برای پاسخ به این سوال کافی است که تنظیمات پنجره OLAP در قسمت Statistics را مطابق با تصویرهای زیر انجام دهیم.

نتیجه اجرای این دستور مطابق با تصویر زیر خواهد بود.

سوال ۵: حداکثر و حداقل فروش و سفارش برای هر نوع کالا در طول سال به تفکیک شیفتکاری چه میزان است؟
پاسخ سوال ۵: برای پاسخ به این سوال، کافی است که فقط متغیر group که مشخص کننده شیفتکاری است را به قسمت Grouping Variable در پنجره مربوط به سوال ۴ اضافه کنیم. نتیجه انجام این دستور به صورت یک جدول محوری خواهد بود که با دو بار کلیک روی خروجی، میتوانید تنظیمات آن را تغییر دهید. همانطور که در تصویر زیر دیده میشود، استفاده از فیلترهای مربوط به متغیر طبقهای، میتواند نتایج جمعبندی را تغییر دهد.

پس از انجام تغییرات روی جدول OLAP، با کلیک روی صفحه خروجی، از حالت ویرایش خارج خواهید شد.
نکته: اگر میخواهید در محیط Syntax یا کد نویسی SPSS این دستور را اجرا کنید باید به کدی مشابه زیر بنویسید:
1DATASET ACTIVATE DataSet1.
2OLAP CUBES purchase sales BY group BY type
3 /CELLS=MIN MAX
4 /TITLE='OLAP Cubes'.جمع بندی داده در SPSS با دستور Case Summary
تقریبا پنجرهای که برای تنظیمات پارامترهای Case Summary ظاهر میشود با پنجره OLAP Cube یکسان است. همانطور که دیده میشود نام این پنجره Summarize Cases بوده و کادرهایی برای مشخص کردن متغیر محاسباتی و متغیر طبقهای با نامهای Variables و Grouping Variables در آن دیده میشود. همانگونه که مشخص است در کادر Variables باید متغیر یا متغیرهایی را قرار دهید که لازم است محاسبات جمعبندی رویشان صورت گیرد. این متغیرها ممکن است از نوع کمی (Scale) یا از نوع کیفی (Nominal-Ordinal) باشند.

همینطور در کادر (Grouping Variable(s نیز اسامی متغیرهای طبقهای قرار میگیرند تا براساس آنها، محاسبات مربوط به جمعبندی تفکیک شده و در خروجی ظاهر شوند.

میتوانید با استفاده از امکانات این پنجره کلیه مشاهدات را هم در خروجی ظاهر کنید. حتی این امکان نیز وجود دارد که در قسمت پایین این پنجره، نمایش مشاهدات را محدود کنید. در ادامه به معرفی این گزینهها خواهیم پرداخت.
- با انتخاب گزینه Display Cases، در پنجره خروجی، گزارشی در مورد وضعیت مشاهدات ظاهر میشود. این گزارش شامل مقادیر همه متغیرها و شماره مشاهدات آنها است. البته اگر تعداد مشاهدات (Cases) زیاد باشد، سطرهای زیادی از خروجی به این امر اختصاص خواهد یافت. بدیهی است با عدم انتخاب این گزینه، مشاهدات در خروجی قرار نگرفته و فقط شاخصها و نتایج جمعبندی ظاهر خواهند شد.
- به منظور کاهش حجم خروجی میتوانید از کادر Limit cases to first، برای تعیین تعداد مشاهداتی که باید در خروجی ظاهر شوند، استفاده کنید. به طور پیشفرض تعداد مشاهدات در این کادر ۱۰۰ در نظر گرفته شده است. به این ترتیب نمونهای از مقادیر مشاهدات در گزارش ظاهر میشود.
- اگر میخواهید فقط مشاهداتی که همه متغیرهای آنها دارای مقدار هستند ظاهر شوند، گزینه Show only valid cases را انتخاب کنید. به این ترتیب سطرهایی از مجموعه داده که دارای مقدار گمشده (Missing Value) هستند در گزارش ظاهر نخواهند شد.
- با انتخاب گزینه Show case numbers، شماره ردیف هر مشاهده نیز در ستون اول خروجی ظاهر میشود.
همچنین در سمت راست پنجره Summarize Cases، دکمههایی برای تعیین ویژگیها محاسباتی و تنظیمات اختیاری (Options) قرار دارد. با فشردن دکمه Statistics، پنجرهای به مانند پنجره Statistics در دستور OLAP Cubes ظاهر میشود که شاخصهای جمعبندی را مشخص میکند. همچنین دکمه Options نیز برای تنظیم عناوین و برچسبهای خروجی به کار میرود. پنجرهای که با فشردن این دکمه ظاهر میشود در تصویر زیر مشخص شده است. عملکرد هر بخش از گزینههای این پنجره نیز در ادامه قابل مشاهده است.

- کادر Title برای نامگذاری جدول خروجی استفاده میشود.
- کادر Caption نیز متنی را مشخص میکند که قرار است در پایین جدول خروجی این دستور ظاهر شود.
- اگر Subheadings for totals را انتخاب کنید، هر بخش از خروجی براساس متغیر طبقهای که در کادر Grouping Variables مشخص کردهاید، دارای عنوان مجزایی خواهد شد.
- با انتخاب کادر ...Exclude cases، در خروجی از نمایش مشاهداتی که دارای مقدار گمشده (Missing Values) هستند جلوگیری خواهد شد.
- ممکن است برای بعضی از انواع متغیرها، یک یا چند شاخص یا محاسبات جمعبندی، میسر نباشد، با وارد کردن علامت یا حرفی برای مشخص کردن این گونه محاسبات در کادر Missing statistics appear as، آنها را متمایز خواهید کرد.
برای پاسخ به سوالات گفته شده، تصویرهای که مربوط به تنظیمات پنجره دستور Case Summary است، در ادامه نمایش داده شدهاند.
سوال ۱: میانگین و انحراف معیار میزان فروش (Sale) چقدر است؟


خروجی به صورت زیر خواهد بود.

سوال ۲: در چند ماه از ماههای سال، فروش کالا از میانگین فروش سالانه کمتر بوده است؟
متاسفانه پاسخ به این سوال در حیطه دستور Case Summary قرار ندارد.
سوال ۳: جمع فروش و میزان سفارش کالا به تفکیک نوع کالا، چقدر است؟

البته توجه داشته باشید که به کمک دکمه Statistics، نوع محاسبه را تابع SUM انتخاب کنید. خروجی این دستور به صورت زیر خواهد بود.

سوال ۴: حداکثر و حداقل فروش و سفارش برای هر نوع کالا در طول سال به چه میزان است؟
برای پاسخ به این سوال کافی است که فقط با استفاده از دکمه Statistics گزینههای Maximum و Minimum را برای محاسبه درخواست کنید. بقیه تنظیمات درست به مانند سوال ۳ خواهد بود. نتیجه مطابق با تصویر زیر است.

سوال ۵: حداکثر و حداقل فروش و سفارش برای هر نوع کالا در طول سال به تفکیک شیفت کاری چه میزان است؟
برای پاسخ به این سوال، درست به مانند پاسخ سوال ۴ عمل کرده ولی متغیر group را هم به قسمت (Grouping Variable(s اضافه میکنیم. خروجی به صورت زیر در خواهد آمد.

همانطور که در جدول خروجی دیده میشود، هر سطح از متغیر طبقهای type با سطوح مختلف متغیر طبقهای group، ترکیب شده و مقدار حداقل و حداکثر فروش و سفارش محاسبه شده است.
نکته: به منظور اجرای این دستورات در محیط Syntax و به صورت کد نویسی، باید مشابه دستوراتی که در ادامه مشاهده میکنید را وارد و اجرا کنید.
1SUMMARIZE
2 /TABLES=purchase sales BY type BY group
3 /FORMAT=NOLIST TOTAL
4 /TITLE='Case Summaries'
5 /MISSING=VARIABLE
6 /CELLS=MIN MAX.خلاصه و جمعبندی
در این نوشتار با نحوه محاسبه بعضی از روشهای جمع بندی در SPSS آشنا شدیم و ویژگیهای هر یک از روشها را هم بازگو کردیم. اغلب نیاز داریم که نتایج حاصل از محاسبات را طی گزارشی، ارائه دهیم در نتیجه بعضی از روشها جمعبندی که به تولید خروجی منجر میشوند در این حالت مسئله کاربرد خواهند داشت، ولی اگر نیاز است که براساس نتایج جمعبندی، تحلیلها و محاسبات دیگری صورت گیرد بهتر است از روشهایی استفاده کنیم که مانند Aggregate باعث بوجود آمدن متغیر جدید خواهند شد.
اگر این مطلب برای شما مفید بوده است، آموزشهای زیر نیز به شما پیشنهاد میشوند:
- مجموعه آموزشهای SPSS
- آموزش آماده سازی داده ها برای تحلیل آماری در SPSS
- مجموعه آموزشهای آمار و احتمال
- رسم نمودار در SPSS — راهنمای کاربردی
- تفکیک فایل داده در SPSS — به زبان ساده
- تحلیل کوواریانس ANCOVA در SPSS — راهنمای کاربردی
^^











مثل همیشه عالی با تشکر از آقای دکتر ری بد