آموزش یادگیری ماشین با مثالهای کاربردی ــ بخش چهارم

فیسبوک قابلیت فوقالعادهای را ساخته و توسعه داده که با استفاده از آن میتواند بلافاصله پس از اینکه تصویری آپلود شد، تشخیص دهد که متعلق به چه کسی است. این شرکت پیش از ارائه ویژگی مذکور، از کاربران میخواست که پس از بارگذاری تصاویر افراد، آنها را با نوشتن نامشان تگ کنند. اکنون و با بهرهگیری از دادههایی که کاربران این شبکه اجتماعی خودشان در اختیار فیسبوک قرار دادهاند، میتواند تصویر افراد را به محض آپلود شدن شناسایی کند.
فیسبوک بهطور خودکار افرادی که قبلا در دیگر تصاویر بارگذاری شده در سایت تگ شدهاند را شناسایی و آنها را تگ میکند.
به این فناوری «تشخیص چهره» (face recognition) گفته میشود. الگوریتم فیسبوک قادر است تصاویر دوستان یک فرد را پس از آنکه صرفا در چند تصویر دیگر تگ شدند، شناسایی کند. چنین فناوری فوقالعاده است و با بهرهگیری از آن، فیسبوک میتواند چهره افراد را با صحت ۹۸٪ تشخیص دهد. این میزان صحت فوقالعاده و تقریبا مشابه توانایی انسان در تشخیص چهره است.
در این مطلب، چگونگی عملکرد روشهای تشخیص چهره مدرن مورد بررسی قرار میگیرد. هدف این نوشته پرداختن به مسائل پیچیدهتر است، از اینرو چالش پیشرو کمی تغییر یافته و سپس مورد بررسی قرار گرفته. در تصویر زیر، فرد سمت چپ چاد اسمیث (Chad Smith) موسیقیدان راک و شخص سمت راست ویل فرل (Will Ferrell) بازیگر معروف است. مسالهای که در این مطلب قرار است حل شود تشخیص چهره این دو فرد از یکدیگر است.

فرد سمت چپ چاد اسمیث و شخص سمت راست ویل فرل است. این دو واقعا دو فرد متفاوت از یکدیگر هستند.
استفاده از یادگیری ماشین در مسائل بسیار پیچیده
در قسمتهای اول، دوم و سوم این مجموعه مطلب، روش حل مسائل «یادگیری ماشین» (Machine Learning) برای یافتن پاسخ چالشهای پیچیدهای که تنها یک گام دارند - مانند تخمین قیمت خانه، تولید دادههای جدید بر پایه دادههای موجود و تعیین اینکه یک تصویر حاوی یک شی خاص است یا خیر - ارائه شد.

همه این مسائل با انتخاب یک الگوریتم یادگیری ماشین، آموزش دادن آن با استفاده از دادهها و دریافت نتیجه قابل حل هستند. اما مساله تشخیص چهره، مجموعهای از مسائل مرتبط با هم است که در ادامه بیان شدهاند.
- ابتدا، نگاه کردن به یک تصویر و پیدا کردن کلیه چهرههای موجود در آن.
- دوم، تمرکز بر هر چهره و توانایی درک اینکه حتی اگر چهره در جهت بدی چرخیده یا در نور نامناسب قرار دارد باز هم متعلق به همان شخص است.
- سوم، توانایی انتخاب ویژگیهای یکتایی که انسانها برای تشخیص تمایز بین افراد استفاده میکنند، مانند بزرگی چشمها، طول چهره فرد و دیگر موارد.
- در نهایت، مقایسه ویژگیهای چهره همه افرادی که در حال حاضر شناخته شدهاند با یکدیگر برای تشخیص نام هر فرد.
ذهن انسان این کارها را بهطور خودکار و آنی انجام میدهد. در حقیقت، انسانها در تشخیص چهره و کشف چهره در اشیا روزمره بیش از اندازه خوب عمل میکنند.

کامپیوترها قادر به انجام چنین سطحی از عمومیسازی نیستند (دستکم در حال حاضر)، بنابراین باید چگونگی انجام این کار طی چند گام از یک فرآیند کلی به آنها آموزش داده شود. ابتدا، نیاز به تبیین مراحلی که برای تشخیص چهره اتفاق میافتد و انتقال خروجی یک گام به گام بعدی است. به عبارت دیگر، چندین الگوریتم «یادگیری ماشین» (Machine Learning) مختلف استفاده شده و به یکدیگر زنجیر میشوند و ورودی هر مرحله در اغلب موارد خروجی مرحله پیشین است.

مراحلی که در تشخیص چهره اتفاق میافتد.
تشخیص چهره ــ گام به گام
برای حل مساله تشخیص چهره، هر بار به یکی از گامهایی پرداخته میشود که پیشتر بیان شد تا با حل گام به گام زیر مسائل، پرسش اصلی پاسخ داده شود. برای هر گام، از الگوریتمهای یادگیری ماشین گوناگونی استفاده میشود. کلیه این الگوریتمها به میزانی که ایده نهفته در پس آنها درک شود و مخاطبان بتوانند با استفاده از آموختههایشان سیستم تشخیص چهره خود را در پایتون با بهرهگیری از OpenFace و dlib بسازند تشریح میشود.

توضیح جزئیات و مفاهیم ریاضی نهفته در پس هر یک از الگوریتمها از حوصله این بحث خارج است و نوشته را از هدف اصلی آن که قابل فهم بودن برای افراد با دانش پایه از «یادگیری ماشین» (Machine Learning) است دور میکند.
گام اول: یافتن همه چهرهها
اولین گام برای حل مساله مطرح شده، تشخیص چهره است. واضح است که پیش از تشخیص اینکه یک تصویر متعلق به چه کسی است، باید خود چهرهها در تصویر تشخیص داده شوند. در اغلب دوربینهایی که از ده ساله گذشته تاکنون مورد استفاده قرار گرفتهاند، توانایی تشخیص چهره به شکلی که در تصویر زیر نشان داده شده وجود دارد.

تشخیص چهره یک ویژگی عالی در دوربینها است. هنگامی که دوربین بهطور خودکار چهره را تشخیص میدهد، میتواند اطمینان حاصل کند که همه چهرهها در مرکز توجه دوربین (فوکوس) قرار دارند. اما، از این قابلیت میتوان برای اهداف متعدد دیگری مانند کشف نواحی از تصویر که قرار است به گام بعد انتقال یابند نیز استفاده کرد.

تشخیص چهره، در اوایل سال ۲۰۰۰ با ابداع روشی توسط پاول ویولا و مایکل جونز مسیر پیشرفت را بهطور خوبی پیمود. این روش سرعت خوبی برای کار روی دوربینهای ارزان داشت. اگرچه، امروزه روشهای قابل اعتمادتری برای انجام چنین کاری وجود دارد. در این مطلب، از روشی برای تشخیص چهره استفاده شده که در سال ۲۰۰۵ ابداع و به آن «هیستوگرام شیبگرا» (Histogram of Oriented Gradients-HOG ) گفته میشود. برای آغاز کار تشخیص چهره در یک تصویر، ابتدا باید آن را سیاه و سفید کرد. زیرا برای این کار نیازی به دادههای رنگی نیست.

سپس، کلیه پیکسلهای موجود در تصویر به یکباره مورد بررسی قرار میگیرند. برای هر پیکسل مجزا، باید پیکسلهایی که مستقیما در اطراف آن قرار دارند بررسی شوند.

هدف، کشف این است که یک پیکسل در مقایسه با پیکسلهایی که اطراف آن را احاطه کردهاند چقدر تیرهتر است. قدم بعدی، ترسیم پیکانی است که نشان میدهد پیکسلها در کدام جهت تیرهتر میشوند.

تنها با نگاه کردن به یک پیکسل که در تصویر نشان داده شده و پیکسلهای کنار آن میتوان تشخیص داد که تصویر در جهت بالا راست تیرهتر شده است.
اگر این فرآیند برای هر پیکسل مجزا در تصویر انجام شود، میتوان هر پیکسل را با یک پیکان جایگزین کرد. این پیکانها «گرادیان» (gradient) نامیده میشوند و در کل تصویر از سمت روشن به تیرهتر هستند. بنابراین، گرادیانها جهت روشنی به تیرگی را در تصویر نمایش میدهند.
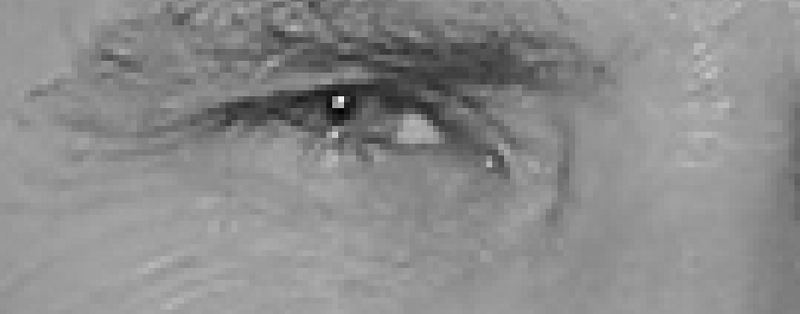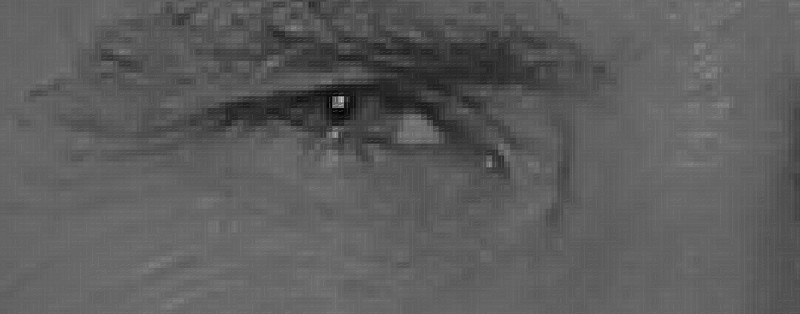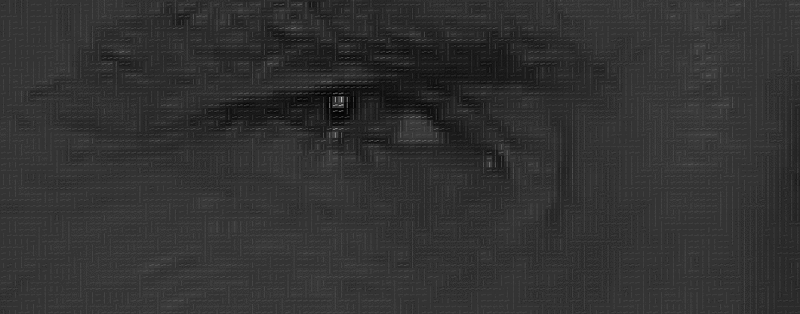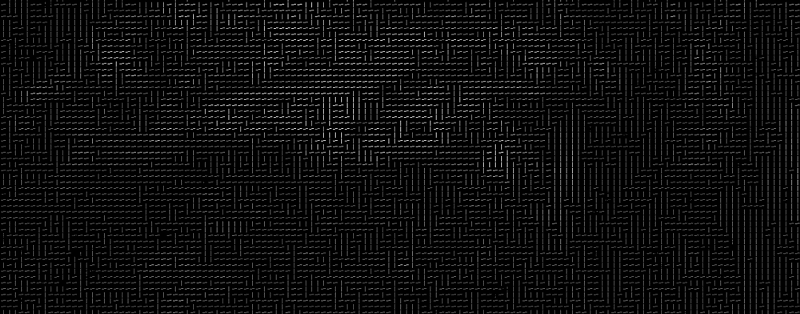
ممکن است به نظر برسد که این کار یک خروجی تصادفی ارائه میکند، در حالیکه دلایل قابل توجهی برای جایگزینی پیکسلها با گرادیانها وجود دارد. اگر پیکسلها بهطور مستقیم تحلیل شوند، تصاویر بسیار تیره و خیلی روشن از یک شخص میتواند مقادیر پیکسل کاملا متفاوتی داشته باشد. اما با در نظر گرفتن جهتی که روشنایی تغییر می کند، هم تصاویر تیره و هم روشن دقیقا با ارائه مشابهی از پیکانها مشخص میشوند. بنابراین، انجام این کار حل مساله را بسیار آسانتر میسازد.
ذخیرهسازی گرادیانها برای هر پیکسل مجزا، جزئیات زیادی را برای تحلیل به ارمغان میآورد. در صورتی که بتوان جهت جریان روشنایی/تاریکی را در سطح بالاتر دید، میتوان الگوی پایهای تصویر را تشخیص داد. برای انجام این کار تصویر به مربعهای کوچکتر ۱۶x۱۶ شکسته میشود. در هر مربع، تعداد نقاط گرادیان در هر جهت خاص (تعداد نقطه بالا، راست بالا، راست و غیره) محاسبه میشوند. سپس، مربعها در تصویر با جهت پیکانها جایگزین میشوند. سرانجام این کار، تبدیل تصویر نهایی به ارائهای بسیار ساده است که ساختار پایهای چهره را به شکل سادهای - متشکل از پیکانها - به تصویر میکشد.

تصویر اصلی تبدیل به یک ارائه HOG میشود که ویژگیهای اصلی تصویر را بدون در نظر گرفتن روشنایی آن ثبت میکند.
برای تشخیص چهرهها در یک تصویر HOG، لازم است بخشی از تصویر کشف شود که بیشترین شباهت را به الگوی HOG شناخته شده در دسته دادههای آموزشی دارد که از دیگر تصاویر آموزش استخراج شدهاند.

با استفاده از این روش، بهسادگی میتوان چهرهها را در هر تصویری یافت.

برای آزمودن این مرحله با استفاده از پایتون، میتوان از کدی که در اینجا قرار داده شده استفاده کرد. این کد چگونگی تولید و نمایش ارائه HOG از تصاویر را نشان میدهد.
گام دوم: نما و طراحی چهرهها
روشی که با استفاده از آن چهرهها در تصاویر مشخص شدهاند خارقالعاده است. اما، اکنون وقت آن رسیده تا به چالش وجود چهرههای مشابه با جهتهای متمایز و چگونگی تشخیص یکی بودن آنها توسط کامپیوتر پرداخته شود.

انسانها میتوانند به سادگی تصاویر ویل فرل را تشخیص دهند، اما کامپیوترها چنین تصاویری (از یک فرد با زوایای متفاوت) را مانند دو فرد کاملا متفاوت از هم میبینند.
برای حل این مساله، تصاویر چرخانده میشوند تا چشمها و لبها همواره در محل نمونه از تصاویر قرار بگیرند. این کار مقایسه چهرهها در تصاویر را آسانتر میکند. در این راستا، از الگوریتمی استفاده خواهد شد که به آن «تخمین نقطه ماشهای چهره» (face landmark estimation) گفته میشود. راههای زیادی برای تخمین نقاط ماشهای وجود دارد، ولیکن در این مطلب از روش ابداع شده توسط وحید کاظمی و جوزف سالوین در سال ۲۰۱۴، استفاده شده است.

ایده اصلی این روش آن است که ۶۸ نقطه مشخص در تصاویر هستند (که به آنها نقاط ماشهای گفته میشود) که در همه چهرهها (بالای چانه، ناحیه بیرونی لبههای چشمها، ناحیه داخلی ابرو و چند جای دیگر) وجود دارند. بنابراین، الگوریتم یادگیری ماشین آموزش میبیند تا توانایی کشف این ۶۸ نقطه در هر تصویر را کسب کند.

۶۸ عنصر در همه چهرهها وجود دارد. این تصویر توسط برندن آموس از CMU ساخته شده، وی روی مبحث OpenFace کار میکند.
در عکس زیر، نتیجه موقعیتیابی ۶۸ نقطه ماشهای چهره در تصویر ویل فرل، ارائه شده است.

میتوان از روش مشابهی برای پیادهسازی فیلتر چهره سهبُعدی زمان واقعی اسنپچت نیز استفاده کرد.
اکنون که محل قرارگیری لبها و چشمها مشخص شد، میتوان تصویر را چرخاند، سپس مقیاس آن را تنظیم و «نگاشت برش» (Shear mapping) را روی آن اعمال کرد تا چشمها و دهان به بهترین شکل ممکن در مرکز تصویر قرار بگیرند. هیچگونه پوشش سهبُعدی ضمن کار استفاده نخواهد شد زیرا منجر به ایجاد بینظمی در تصویر میشود. برای پردازشهای بعدی، صرفا تبدیلهای پایهای عکس شامل چرخش و تبدیل مقیاسی که خطوط موازی را حفظ میکند انجام خواهد شد (به آن «تبدیل آفین» (Affine transformation) گفته میشود).

اکنون، بیتوجه به اینکه چهره در چه جهتی چرخیده، مدل قادر به قرار دادن چشمها و دهان در مرکز تصویر و در یک ناحیه مشابه برای همه تصاویر شخص است. انجام این کار بر صحت گام بعدی می افزاید. برای انجام دادن این مرحله، در صورت استفاده از زبان برنامهنویسی پایتون و کتابخانه dlib، میتوان از این قطعه کد برای پیدا کردن نقاط ماشهای چهره استفاده کرد. همچنین، کد تبدیل تصویر با استفاده از نقاط ماشهای نیز در دسترس است.
گام سوم: رمزنگاری چهرهها
در این مرحله به مساله اصلی - یعنی تشخیص چهره فرد - پرداخته خواهد شد. با ادامه راه، جذابیت مساله نیز بیشتر میشود. سادهترین رویکرد برای تشخیص چهره آن است که تصویر ناشناخته یافت شده در گام دوم را با همه تصاویر موجود از اشخاصی که تاکنون تگ شدهاند مقایسه کرد. هنگامی که تصویر چهره ناشناخته با یکی از تصاویر موجود تطابق پیدا کرد، میتوان نتیجه گرفت این دو شخص مشابه هستند. چنین رویکردی به نظر خوب میرسد.
اما یک مشکل بسیار بزرگ در این رویکرد وجود دارد. سایتهایی مانند فیسبوک که دارای میلیونها کاربر و چندین تریلیون تصویر هستند، نمیتوانند برای هر عکس جدید، در تصاویر از پیش تگ شده گردش حلقهای داشته باشند، زیرا این کار زمان زیادی میبرد. چنین سایتهایی نیاز دارند که چهره را نه طی ساعتها بلکه در چند میلیثانیه تشخیص دهند.
بنابراین، نیاز به روشی برای استخراج سنجههای پایهای هر چهره است. با استفاده از این سنجهها میتوان چهره ناشناخته را اندازهگیری کرد. سپس، تصویری که نزدیکترین مقادیر را به سنجههای حاصل شده دارد به عنوان فرد مشابه برگزید و از نام آن برای تگ کردن چهره ناشناخته بهره برد. به عنوان مثالی برای این سنجهها، میتوان به سایز گوشها، فاصله بین چشمها، طول بینی و دیگر موارد اشاره کرد. چنین ایدهای در برخی فیلمهای جنایی از جمله تحقیقات صحنه جرم (سیاسآی) به تصویر کشیده شده.

درست مانند یک فیلم
قابل اعتمادترین روش برای اندازهگیری چهره
پرسشی که در این مرحله مطرح میشود این است که چه سنجههایی را از هر چهره باید برای ساخت یک پایگاه داده از چهرههای شناخته شده گردآوری کرد؟ سایز گوش؟ طول بینی؟ رنگ چشم؟ چه چیز دیگری؟ سنجههایی مانند رنگ چشم که برای انسانها معنا دارند، برای کامپیوترهایی که به هر پیکسل بهطور مجزا نگاه میکنند بیمعنی محسوب میشوند.
پژوهشگران کشف کردهاند که صحیحترین رویکرد برای تعیین سنجهها آن است که اجازه دهند کامپیوتر خود تشخیص دهد چه مواردی مناسب هستند و آنها را گردآوری کند. «یادگیری عمیق» (Deep Learning) در کشف قسمتهایی از چهره که باید اندازهگیری شوند نسبت به انسان عملکرد بهتری دارد.
از همین رو، شبکه عصبی پیچشی باید برای گردآوری سنجهها آموزش داده شود (مانند کاری که در بخش سوم انجام شد). اما به جای آموزش دادن شبکه عصبی جهت تشخیص اشیای تصویر که در مطلب پیشین انجام شد، اکنون شبکه آموزش میبیند تا ۱۲۸ سنجه را برای هر چهره تولید کند. فرآیند آموزش با نگاه کردن به سه تصویر چهره در هر بار عمل میکند. مراحل ساده این عملکرد در ادامه آمده است.
- تصویر چهره آموزش از یک شخص شناخته شده را بارگذاری کن
- تصویر دیگری از همان شخص بارگذاری کن
- تصویر چهره یک شخص کاملا متفاوت را بارگذاری کن
اکنون، الگوریتم به سنجههایی که برای هر سه تصویر تولید کرده نگاه میکند. سپس، شبکه عصبی را اندکی میچرخاند تا اطمینان حاصل کند که سنجههای تولید شده برای ۱# و ۲# اندکی به هم نزدیکتر و سنجههای ۲# و ۳# کمی از یکدیگر دورتر هستند.

پس از میلیونها بار تکرار این گام برای میلیونها تصویر از هزاران فرد گوناگون، شبکه عصبی میآموزد که بهطور قابل اعتمادی ۱۲۸ سنجه را برای هر شخص تولید کند. هر ده تصویر متفاوت از یک شخص باید دارای سنجههای تقریبا مشابهی باشند.
کارشناسان یادگیری ماشین به این ۱۲۸ سنجه «embedding» میگویند. ایده تقلیلِ دادههای خام پیچیده مانند تصاویر به لیست اعداد تولید شده توسط کامپیوتر در «یادگیری ماشین» (Machine Learning) به ویژه در ترجمه زبان کاربرد دارد. رویکرد اصلی که برای کاهش حجم چهرهها در این مطلب استفاده شده توسط پژوهشگران گوگل در سال ۲۰۱۵ تولید شده، ولیکن روشهای متعددی برای انجام این کار موجود است.
رمزنگاری تصویر چهره این مساله
فرآیند آموزش دادن یک شبکه عصبی پیچشی که بتواند embeddingهای چهره را به عنوان خروجی ارائه کند نیازمند حجم داده و قدرت پردازش بسیار بالا خواهد بود. حتی با استفاده از یک کارت گرافیک NVidia Tesla نیاز به ۲۴ ساعت زمان ممتد برای آموزش دادن مدل جهت کسب صحت مناسب است.
پس از آنکه شبکه آموزش دید، میتواند سنجهها را برای کلیه چهرهها تولید کند، حتی اگر آنها را پیش از این ندیده باشد. بنابراین این گام تنها یک مرتبه انجام میشود. خوشبختانه، تیم فعالی در OpenFace این کار را انجام داده و چندین شبکه آموزش دیده را برای عموم منتشر کردهاند که میتوان از آنها برای گردآوری سنجهها استفاده کرد. اکنون، تنها کاری که نیاز است انجام شود اجرای تصاویر در شبکه از پیش آموزش دیده برای دریافت ۱۲۸ سنجه هر چهره است. در تصویر زیر این سنجهها نشان داده شدهاند.

این ۱۲۸ بخش چهره دقیقا کدام نواحی هستند؟ انسانها نه تنها ایدهای در این رابطه ندارند بلکه برای آنها اهمیتی نیز ندارد. تنها مورد حائز اهمیت آن است که شبکه با نگاه کردن به دو تصویر متفاوت یک فرد، اعداد مشابهی را تولید میکند. برای آزمودن این روش، OpenFace یک اسکریپت به زبان برنامهنویسی «لوآ» (lua) آماده کرده است. این اسکریپت برای همه تصاویر موجود در یک پوشه، کلیه embeddingها را تولید کرده و آنها را در یک فایل csv مینویسد. روش اجرای این الگوریتم در اینجا بیان شده.
گام ۴: پیدا کردن نام فرد از رمزنگاری
آخرین گام در کل این فرآیند، سادهترین مرحله آن نیز هست. فقط کافیست مدل، فرد را در پایگاه داده افراد شناخته شده با یافتن نزدیکترین سنجه به تصویر آزمون، بیابد. برای این کار فقط از الگوریتم پایه دستهبندی استفاده میشود. نیازی به استفاده از هیچ ترفند «یادگیری ماشینی» (Machine Learning) نیز نیست. روش مورد استفاده در این مطلب، یک الگوریتم طبقهبندی ساده خطی به نام ماشین بردار پشتیبان است. این در حالیست که الگوریتمهای طبقهبندی متعددی برای این مساله جوابگو هستند.
اکنون باید دستهبندی را آموزش داد تا بتواند این سنجهها را برای یک تصویر جدید بگیرد و بگوید که آیا فرد شناخته شدهای وجود دارد که با این الگو مطابقت داشته باشد. اجرای این دستهبندی تنها چند میلی ثانیه زمان میبرد. بنابراین، اکنون وقت آزمودن سیستم رسیده است. ابتدا طبقهبند با embedding بیست تصویر از ویل فرل و جیمی فالون آموزش داده میشود.

دادههای آموزش
سپس، دستهبند روی هر فریم از ویدئو محبوب ویل فرل و چاد اسمیث که تظاهر میکنند دیگری هستند اجرا شده است.

این برنامه را به سادگی اجرا کنید
کلیه گامهای انجام شده برای حل مساله مطرح در ادامه مرور میشوند.
- تصویر را با استفاده از الگوریتم HOG رمزنگاری کرده تا نسخه ساده شده آن حاصل شود. با استفاده از تصویر سادهسازی شده، بخشی از تصویر که بیش از سایر موارد به رمزنگاری HOG چهره عمومی سازی شده مشابه است پیدا میشود.
- ژست چهره با پیدا کردن نقاط ماشهای اصلی در تصویر یافت میشود. پس از کشف این نقاط ماشهای، از آنها برای پوشاندن تصویر به منظور قرارگیری دهان و چشمها در مرکز تصویر استفاده میشود.
- تصویر چهره قرار گرفته در مرکز به شبکه عصبی که چگونگی اندازهگیری ویژگیهای چهره را میداند داده میشود. ۱۲۸ سنجه حاصل ذخیره میشوند.
- همه چهرههایی که در گذشته اندازهگیری شدهاند مورد بررسی قرار میگیرند تا مشخص شود کدام فرد نزدیکترین سنجهها را به این فرد دارد.
در ادامه یک راهنمای گام به گام برای انجام کلیه گامهای این فرآیند روی کامپیوتر مخاطبان آمده است.
پیش از آغاز
کاربر ابتدا باید از نصب بودن پایتون، OpenFace و dlib اطمینان حاصل کند. همچنین میتواند این موارد را به صورت دستی نصب کرده یا از یک ایمیج داکر (docker image) از پیش پیکربندی شده که همه چیز را به صورت نصب شده دارد استفاده کند.
1docker pull bamos/openface
2docker run -p 9000:9000 -p 8000:8000 -t -i bamos/openface /bin/bash
3cd /root/openfaceنکته: کاربرانی که از داکر روی OSX استفاده میکنند، میتوانند پوشه /OSX /Users را درون ایمیج داکر به صورت زیر فعال کنند:
1docker run -v /Users:/host/Users -p 9000:9000 -p 8000:8000 -t -i bamos/openface /bin/bash
2cd /root/openfaceاکنون میتوان به همه فایلهای OSX درون ایمیج داکر از طریق .../host/Users/ دسترسی داشت.
1ls /host/Users/گام اول
پوشهای با عنوان /training-images/. را باید درون پوشه openface ساخت.
1mkdir training-imagesگام دوم
برای هر فردی که قرار است چهره آن تشخیص داده شود، باید یک زیرپوشه ساخته شود.
1mkdir ./training-images/will-ferrell/
2mkdir ./training-images/chad-smith/
3mkdir ./training-images/jimmy-fallon/گام سوم
کلیه تصاویر هر فرد از زیر پوشه صحیح و مربوط به خودش کپی شود. همچنین، باید اطمینان حاصل شود که در هر تصویر تنها یک چهره وجود داشته باشد. نیازی به بریدن تصویر دور چهره نیست. OpenFace این کار را به صورت خودکار انجام میدهد.
گام چهارم
اسکریپت openface از دایرکتوری ریشه آن اجرا شود.
حالا، ابتدا باید ژست چهره تشخیص داده و ترازبندی انجام شود.
1./util/align-dlib.py ./training-images/ align outerEyesAndNose ./aligned-images/ --size 96
2کد بالا یک زیرپوشه /aligned-images/. از نسخههای بریده و تراز شده هر تصویر آزمون ایجاد میکند.
سپس، ارائهای از هر تصویر تراز شده فراهم شود.
1./batch-represent/main.lua -outDir ./generated-embeddings/ -data ./aligned-images/
2پس از اجرای خط کد بالا، زیرپوشه /generated-embeddings/. شامل یک فایل csv با embeddingهای هر تصویر خواهد بود.
اکنون، مدل تشخیص چهره باید آموزش داده شود.
1./demos/classifier.py train ./generated-embeddings/
2این کار موجب ساخت فایلی با عنوان generated-embeddings/classifier.pkl/. میشود. این فایل یک مدل ماشین بردار پشتیبان است که برای تشخیص چهرهها استفاده میشود.
گام پنجم: تشخیص چهره!
مانند خط کد زیر، یک تصویر جدید از چهرهای ناشناخته به اسکریپت دستهبندی داده شود.
1demos/classifier.py infer ./generated-embeddings/classifier.pkl your_test_image.jpg/.
2خروجی پیشبینی به صورت زیر است.
1=== /test-images/will-ferrel-1.jpg ===
2Predict will-ferrell with 0.73 confidence.نکات مهم:
- اگر نتایج مناسب نبود، باید تعداد بیشتری تصویر از هر شخص به گام سوم اضافه شود (به ویژه تصاویری در ژستهای گوناگون)
- این اسکریپت همیشه پیشبینی ارائه میکند، حتی اگر چهره متعلق به فردی باشد که نمیشناسد. در کاربردهای جهان واقعی، به امتیاز اطمینان بیان شده در خروجی مدل نگاه شده و از پیشبینیهایی با امتیاز اطمینان کم چشمپوشی میشود زیرا اغلب اشتباه هستند.

بخش پنجم این مجموعه مطلب را مطالعه کنید.
اگر نوشته بالا برای شما مفید بود، آموزشهای زیر نیز به شما پیشنهاد میشوند:
- آموزش یادگیری ماشین
- آموزش مقدمهای در رابطه با یادگیری ماشین با پایتون
- گنجینه آموزشهای یادگیری ماشین و دادهکاوی
- کاربرد جبر خطی در علم دادهها و یادگیری ماشین
^^










